研究内容紹介
5.2 音声ガイドの研究
視覚に障害がある方にもテレビのスポーツ中継を楽しんでいただくために、生放送番組にも対応可能な新たな解説放送サービス「音声ガイド」の研究に取り組んでいる。解説放送を補完する新たな視覚障害者サービス「自動解説放送」と、アナウンサー実況の代わりとしてネットサービス等に展開する「ロボット実況」、およびこれらのベースとなる音声合成技術の研究を進めた。
■自動解説放送
人手で制作されている解説放送と同様に、自動解説放送も放送音声とできるだけ重ならないことが望ましい。そこで、発話の音響的な特徴の変化傾向から、解説の好ましい挿入タイミングを自動推定する手法の検討を行った。リアルタイムで動作するプロトタイプを試作し、技研公開2018で展示した。本手法で推定したタイミングと、目視で確認した挿入可能なタイミングとを比較した結果、一定の有効性が示された(1)(2)。また、視覚障害者を対象に、発話の重なりが避けられない状況下での好ましい聴取条件について評価実験を行った結果、重なっても影響が少ない条件や、逆に、絶対に回避すべき条件などが確認され、システム設計への指針を得た。
また、聞き取りやすい解説音声の音響的特徴の検討や、スポーツ以外の番組へ展開について、視覚障害者および放送現場と連携してサービス実施の可能性を検討した。
■ロボット実況
ロボット実況とは、国際的なスポーツ大会などで提供されるリアルタイム競技関連データから、競技の状況を説明する実況原稿を自動で生成し、合成音声により発話させる技術である(3)。2018年に開催されたスポーツ大会では、一部競技でインターネット配信によるロボット実況サービスを実施したが、2020年の大会に向けて発話の内容をさらに充実させ、かつ、より多くの競技に付与できるよう、発話アルゴリズムの改良および必要なデータを取得する方法の検討を進めた。
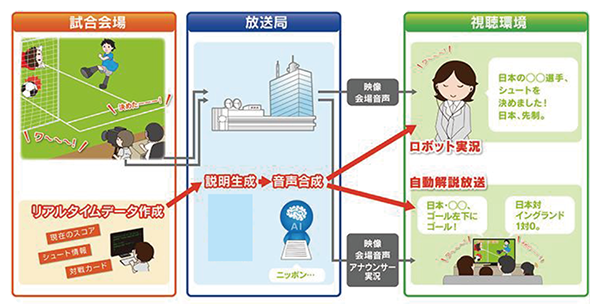
図5-3 書き起こしインターフェース
■音声合成技術
2017年度に開発したDNN(Deep Neural Network)音声合成技術を、“ニュースチェック11”のCGレポーター「ヨミ子」の声として実用化した。番組演出のニーズに応じて、多様な発話表現に対応可能なデータの整備や操作プログラムの改修を行い、イントネーションやポーズの改善、会話口調の実現など、番組活用を通した発話スキルの向上に取り組んだ。この技術はインターネット上のニュース読み上げサービスにも活用されている。並行して、合成音の更なる品質向上と、コストと時間を要している発話モデルの学習データ整備の効率化につながる、新たな音声合成技術の開発に着手した(4)(5)。
また、地域放送局のラジオ気象情報の一部を音声合成で提供するトライアルに向けて、アナウンサー品質の発話を実現するDNN音声合成技術を開発した。発話を気象予報番組の内容に限定することで高品質化を実現した。2019年3月に甲府放送局のラジオ県域放送でのテスト放送を開始した。
その他、既開発の話速変換技術を利用し、ヨミ子のネットコンテンツ展開を支援した。早口言葉を流暢に読み上げる演出や、ニュース解説の動画の音声に話速の緩急を付与しつつ所定時間に縮める機能の追加を行った。また、既開発の音声処理技術を応用し、昨年度に続きEテレ「テレビで中国語」で、中国語学習アプリ「声調確認くん」や「そり舌確認くん」の運用支援を継続した。
| 〔参考文献〕 | |
| (1) | M. Ichiki, T. Shimizu, A. Imai, T. Takagi, M. Iwabuchi, K. Kurihara, T. Miyazaki, T. Kumano, H. Kaneko, S. Sato, N. Seiyama, Y. Yamanouchi and H. Sumiyoshi:“A Study of Overlap between Live Television Commentary and Automated Audio Descriptions,” Miesenberger, K. et al. eds., Springer, 2018, pp.220-224 (2018) |
| (2) | 一木,熊野,今井,都木:“生放送番組向けの自動解説音声の挿入タイミング決定法 -スポーツ中継における実況音声の発話末予測-,”信学技報, Vol.118, No.270, WIT2018-29, pp.45-50 (2018) |
| (3) | K. Kurihara, A. Imai, N. Seiyama, T. Shimizu, S. Sato, I. Yamada, T. Kumano, R. Tako, T. Miyazaki, M. Ichiki, T. Takagi and H. Sumiyoshi:“Automatic Generation of Audio Descriptions for Sports Programs,” SMPTE Motion Imaging Journal(2019) |
| (4) | 栗原,清山,熊野,今井:“読み仮名と韻律記号を入力とする日本語End-to-End 音声合成方式の検討,” 音響学会秋季講演論文集, 1-4-1(2018) |
| (5) | 栗原,清山,熊野,今井:“日本語end-to-end音声合成における発話スタイル制御に関する検討,” 映情学年次大, 12C-1(2018) |