Research Area
5.2 Audio description technology
We are researching "audio description" technologies, which produce voice explanations for live broadcast programs so that people with visual impairment can enjoy live sports programs better. We studied "automated audio description," which supplements human commentaries with auxiliary voice explanations for visually impaired people, "robot commentary," which provides commentaries for internet services in place of human announcer, and a speech synthesis technology, which is the base of these technologies.
■Automated audio description
As with manually produced audio descriptions, an automated audio description should not overlap with program speech to the extent possible. We studied a technique to estimate a desirable timing for inserting a commentary from the variation trend of acoustic features of speech. We developed a prototype system that operates in real time and exhibited it at the NHK STRL Open House 2018. The results of comparison between the timings estimated by this technique and the timings which are visually confirmed to be ready for an insertion demonstrated a certain level of effectiveness(1)(2). We also conducted evaluation experiments participated by visually impaired people on favorable hearing conditions under a situation where speech overlaps cannot be avoided. The results clarified the conditions which give little influence even if an overlap occurs and the conditions which must be prevented, demonstrating guidelines for system design.
Additionally, we investigated the acoustic features of easy-to-hear commentary speech and studied the feasibility of expanding service to non-sports programs in cooperation with visually impaired people and program producers.
■Robot commentary
Robot commentary is a technology to automatically generate commentary manuscripts describing the situation in games from real-time competition data provided in international sports competitions and to read out the manuscripts with synthesized speech(3). We provided a robot commentary service for some sports via internet delivery at a sports event held in 2018. With the aim of enriching the content of speech and providing commentaries for more sports in an event to be held in 2020, we improved the speech algorithm and studied a way of collecting necessary data.
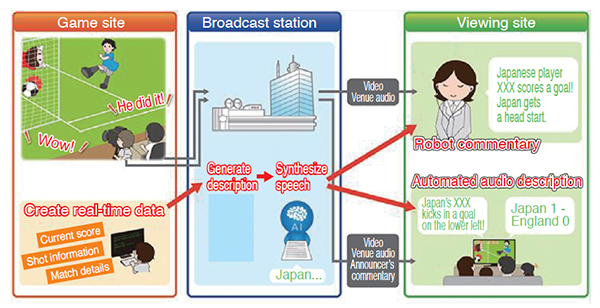
Figure 5-2. Mechanism of automated audio description and robot commentary
■Speech synthesis technology
As a practical application of the speech synthesis technology using deep neural networks (DNNs) that we developed in FY 2017, we developed the voice of CG reporter "Yomiko" for a program "News Check 11." We prepared necessary data and modified the operation program to enable the handling of diverse speech expressions according to production effect needs and improved utterance skills such as intonations, poses and conversational tones through actual use in programs. This technology is also utilized for news reading service on the internet. Concurrently, we began developing a new speech synthesis technology that could bring further quality improvement of synthesized speech and higher efficiency of the preparation of training data for a speech model, which currently takes significant costs and time(4)(5).
We developed a DNN speech synthesis technology to realize speech with an announcer-equivalent quality for a trial service in which the radio weather information of regional broadcasting stations will be partly provided by speech synthesis. We achieved high-quality speech by limiting the content of speech to weather forecast programs. We began test broadcasts in prefectural-area radio broadcasting by the Kofu station in March 2019.
Additionally, we helped promote the use of Yomiko for internet content by using a speech rate conversion technology that we previously developed. We added a production effect to read tongue twisters fluently and a function to shorten the speech of news commentary video to fit in a specified time by varying the speech speed. We also continued to support the operation of Chinese learning applications, "Seicho Kakunin-kun (Tone Checker)" and "Sorijita Kakunin-kun (Retroflexion Checker)," in an Educational TV program "Learn Chinese on TV" by applying a speech processing technology that we previously developed.
| [References] | |
| (1) | M. Ichiki, T. Shimizu, A. Imai, T. Takagi, M. Iwabuchi, K. Kurihara, T. Miyazaki, T. Kumano, H. Kaneko, S. Sato, N. Seiyama, Y. Yamanouchi and H. Sumiyoshi: "A Study of Overlap between Live Television Commentary and Automated Audio Descriptions," Miesenberger, K. et al. eds., Springer, 2018, pp.220-224 (2018) |
| (2) | M. Ichiki, T. Kumano, A. Imai and T. Takagi: "Timing determination method to insert an automated audio description in live television broadcast," IEICE Technical Report vol.118, no.270, WIT2018-29, p.45-50 (2018) (in Japanese) |
| (3) | K. Kurihara, A. Imai, N. Seiyama, T. Shimizu, S. Sato, I. Yamada, T. Kumano, R. Tako, T. Miyazaki, M.Ichiki, T. Takagi and H. Sumiyoshi: "Automatic Generation of Audio Descriptions for Sports Programs,"SMPTE Motion Imaging Journal (2019) |
| (4) | K. Kurihara, N. Seiyama, T. Kumano and A. Imai: "Study of Japanese End-to-End speech synthesis method that inputting kana and prosodic symbols," Proc. of ASJ fall general conference 1-4-1 (2018) (in Japanese) |
| (5) | K. Kurihara, N. Seiyama, T. Kumano and A. Imai: "Study on switching method of speaking styles in Japanese end-to-end speech synthesis," Proc. of ITE winter conference 12C-1 (2018) (in Japanese) |