Research Area
4.1 Social big data analysis technology
■Social media analysis technology
We are researching ways to collect the information useful for program production from a massive amount of text data handled by broadcasters ("text big data"). News producers collect newsworthy information from social media posts, which are a form of text big data. To support this effort, at NHK STRL, we are developing a system to automatically collect newsworthy posts in real time from Twitter by using the newsworthy posts previously obtained in news production sites as supervised data for machine learning. This system extracts newsworthy information from a huge amount of tweets by using neural networks (NNs). At present, however, this system identifies several thousands of tweets per day as newsworthy. We therefore developed a user interface to classify the extracted posts by news category automatically determined for the tweet and by the name of place (Figure 4-1)(1). To improve the function to identify the place of an incident or accident, we studied a method for estimating the poster's location information using graph convolutional NNs with knowledge-based information (2).
Newsworthy tweets identified by the system can contain comments for or retweets of the information already reported by other news media. To determine such tweets, we developed a method for identifying reported information using convolutional NNs(3). In social media, there are many accounts which make automatic posts, called "bots". Since posts by bots often contain copies of past posts, groundless rumors and so-called fake news, the information on whether the account of a certain post is a bot or not is important for program producers. To meet this demand, we developed a method for determining bot accounts on the basis of the regularity of the time of posting to social media(4).
Twitter contains tweets about a wide variety of incidents and accidents happening in the world and some of them may not be able to be handled by a fixed model. We therefore developed a system that allows its model to be updated using new training data prepared on the basis of the operation logs of system users(5). Because some of the posts about incidents and accidents contain only images attached without text information indicating a fire or traffic accident, we researched a function to extract relevant tweets using not only text analysis but also image classification technologies to be introduced in 4.2 and implemented it into our system.
Broadcasters have accumulated information about programs that they produced in the past, which is useful for producing new programs. We developed a function to retrieve and present the information of relevant past programs on the basis of the collected social media posts by using a method for determining the relation between sentences using our semantic relations dictionary (Figure 4-2)(6).
We utilized the visualization function and analysis function of our system for live broadcast programs reflecting viewer opinions (Tengo-chan, Hajikko Revolution) and a year-end special program (Document 72 Hours). We also participated in the Incident Streams track at the TREC 2018 competition workshop held by the U.S. National Institute of Standards and Technology (NIST) and achieved excellent results (4th place in Information Type Categorization Task and 1st place in Information Priority Task)(7).
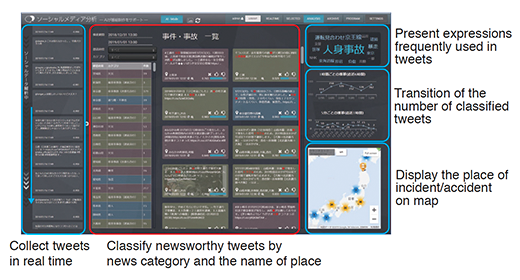
Figure 4-1. User interface for social media analysis system
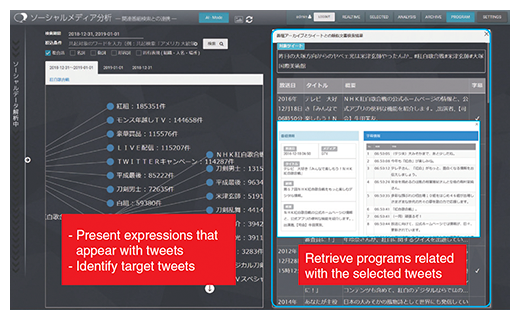
Figure 4-2. Retrieval of related programs on the basis of social media posts
■Opinion analysis technology
We are researching a technology to analyze opinions about programs comprehensively and constantly after broadcast. Opinions about programs contain not only opinions purely about program content but also requests for programming and business, covering a range of specific opinion types. We implemented an algorithm capable of classifying these opinions from the perspective of practical work of viewer opinion analysis into an analysis system that can be used by relevant departments.
We identified challenges for developing a technology for detecting the target of opinion, which is one of the important factors for determining that the opinion is concerning a program. Some of the conventional methods using social networking services (SNSs) use program hashtags, a notation peculiar to Twitter users, as clues. Program hashtags, however, are influenced by changes in how they are used in social media and the revisions of broadcasters' operation guidelines. It is therefore necessary to develop a method not excessively dependent on program hashtags in order to enable comprehensive and constant analysis. To meet this requirement, we investigated the advantages and disadvantages of methods using program hashtags and studied a method that uses a general language processing technology as clues.
| [References] | |
| (1) | Y. Takei, K. Makino, T. Miyazaki, H. Sumiyoshi and J. Goto: "Social Media Analysis System for News Gathering Support," FIT 2018, E-015(2018) (in Japanese) |
| (2) | T. Miyazaki, A. Rahimi, T. Cohn and T. Baldwin: "Twitter Geolocation using Knowledge-Based Methods," W-NUT2018, pp.7-16 (2018) |
| (3) | K. Makino, Y. Takei, T. Miyazaki and J. Goto: "Classification of Tweets about Reported Events using Neural Networks," W-NUT2018, pp.153-163 (2018) |
| (4) | H. Okamoto, T. Miyazaki and J. Goto: "Humans are Ambiguous and Capricious: Bot Detection Focusing on Statistical and Signal-Like Property of Tweeting Activities," IPSJ2019, 7K-02 (2019) (in Japanese) |
| (5) | K. Makino, Y. Takei, H. Okamoto, T. Miyazaki and J. Goto: "A Study on Multitask Learning Methods for Extracting Important Tweets," ITE Winter Convention,12C-3 (2018) (in Japanese) |
| (6) | T. Miyazaki, K. Makino, Y. Takei, H. Sumiyoshi and J. Goto: "TV Program Retrieval from Tweets for Supporting TV Program Creation," ITE Annual Convention, 13B-5 (2018) (in Japanese) |
| (7) | T. Miyazaki, K. Makino, Y. Takei, H. Okamoto and J. Goto: "NHK STRL on the IS track of the TREC 2018," TREC2018 (2018) |