発話順序に基づくGraph Attention Networksを用いた対話文における感情認識
放送局における番組制作の過程では,SNS上で話題となっている出来事を活用することが多い。話題の調査を目的として,ツイートに含まれる頻出単語をもとに,社会的に関心の高いキーワードを取得している。しかし,このように得られたキーワードには広告などが多く含まれ,番組制作に不要なものを多く抽出してしまう課題がある。そこで,投稿が示す感情極性を利用し,番組制作に有用な投稿を取得する研究を進めている。本稿では,投稿される発話文から感情ラベルを推測するとともに,リプライなどの対話文も利用することで高精度な感情ラベルを推定する手法について述べる。対話文における各発話の感情は,発話の内容だけでなく発話間の関係が大きな影響を与えることが知られている。この性質を利用した従来手法では,発話間の関係の中でも特に自己依存と相互依存に着目し,RGAT (Relational Graph Attention Networks)を用いて取得することで,当時の世界最高峰の認識精度を獲得した。しかしながら,RGATは発話の順序情報を利用できない課題がある。そこで本稿は,RGATに発話順序を加える新たな手法を提案する。提案手法を用いることで,自己依存と相互依存を含む発話間の関係と,発話の順序情報の両方を利用できるようになる。対話文における感情認識における3つのベンチマークデータセットについて評価実験を行い,2つのデータセットで従来手法を上回る認識精度を達成し,世界最高峰の認識精度を達成した。
1.はじめに
放送局における番組制作過程では,SNS上で話題となっている出来事を活用することが多い。話題の調査を目的に,ツイートに含まれる頻出単語をもとに,社会的に関心の高いキーワードを取得している。しかし,このように得られたキーワードには企業の広告などが多く含まれ,番組制作に不要なものを提示してしまう課題がある。そこで,リツイート等の反響件数だけでなく,投稿が示す感情極性を利用し,番組制作に有用な投稿を取得する研究を進めている1)。SNS上の感情表現は現実の出来事の発生を反映することが知られているため2),感情の変化に着目し情報を絞ることによって,番組制作に有用な情報を抽出している。
SNS上の投稿は,一般的に感情を表すラベルが付与されない。したがって,どのような感情を示しているかを推定する必要がある。そこで本稿では,投稿される発話文から感情ラベルを推測すると同時に,リプライ等の対話文(1図)も活用することで感情ラベルの推定精度を改善する手法について述べる。一般に,発話に現れる感情は,本人の発話だけでなく,他者の発話の影響を受けることが知られている3)。したがって,他の発話との関係性も考慮することで,感情認識の精度向上を期待できる。
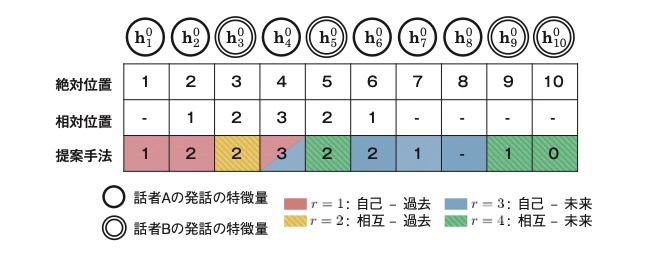
近年の対話文における感情認識技術の多くは,発話の内容を抽出する機構に加えて発話間の関係性を利用する機構も備えている。DialogueRNN(Recurrent Neural Network)4)は,発話の内容と発話間の関係,そして感情の移り変わりをそれぞれGRU (Gated Recurrent Unit)*1 でモデリングし,高い感情認識の精度を達成した手法である。しかし,この手法は発話間の関係の中でも特に,自身の発話からの影響 (自己依存) と他者の発話からの影響 (相互依存)を考慮していない課題がある。1図を用いて,2つの依存関係の重要性を示す。1図は,2人の話者が就職活動について意見を交わす例である。話者Aは就職先が見つからないため,一連の発話で負の感情を抱いている。これは自分自身の感情の推移を示し,自己依存を表す。一方で,話者Bの4番目の感情は,直前の話者Aの状況に同情し,負の感情に変化している。これは他者の発話が自身の感情に影響を与える性質を示し,相互依存を表す。
Ghosalらは,グラフ*2 深層学習モデル(GNNs: Graph Neural Networks)*3 の一つであるRGAT*4 を用いて,自己依存と相互依存の関係を獲得し,当時の世界最高峰の認識精度を達成した5)。この手法は,グラフ深層学習におけるノードに対して各発話の特徴量を,エッジに対して発話間の関係を,エッジの種類に対して依存関係の種類を設定し,有向グラフ*5を構築する。しかしながら,RGATを含むGNNは対話文中の発話の順序情報を利用できない課題がある。
1図を用いて,順序情報の重要性を説明する。話者Bは4番目の発話で感情が変化する。これは,1番目や2番目の発話ではなく,直前の3番目の発話に同情したことが原因と考えられる。したがって,発話から発話への距離の影響を考慮することで,認識精度の向上が期待できる。
順序情報を付与する一般的な解決策として,発話の絶対位置6)や相対位置7)を基にした位置表現を,GNNに加える方法がある。絶対位置を基にした位置表現はGNNのノード (発話)に加えられ,相対位置を基にした位置表現はGNNのエッジ(発話間の関係)に加えられる。一方で,Ghosalらの手法5)を参考にする提案手法は,自己依存と相互依存を考慮するために,依存関係の種類に応じたRGATを用いる。したがって,絶対位置や相対位置ではなく依存関係の種類に応じた位置表現を用いることで,認識性能の向上が期待できる。
本論文は,依存関係の種類に応じて新しい位置表現を作成し,それをRGATに加える新たな手法を提案する。提案手法を用いることで,自己依存と相互依存を含む発話間の関係と,発話の順序情報の両方を利用することができる。対話文における感情認識における3つのデータセットを用いて評価実験を行い,2つのデータセットで従来手法を上回り,世界最高峰の認識精度を達成した8)。さらに,絶対位置や相対位置を基にした位置表現を加える手法と比較し,依存関係の種類に応じた位置表現が,認識精度の向上に貢献することも確認した。

2.関連研究
多くの研究者が対話文における感情認識の研究に取り組んでいる。中でも,DialogueRNN4)は発話の内容と発話間の関係,そして感情の移り変わりをそれぞれGRUでモデリングし,精度向上に大きく貢献した。提案手法に最も関連する手法として,DialogueGCN5)がある。DialogueGCNは,自己依存と相互依存を取得するためにRGATモデルを利用し,当時の世界最高峰の認識精度を達成した手法である。
また,位置表現の追加方法に関連するモデルとして,Transformer 6)がある。Transformerは注意機構*6 を基に構成されるため,時系列情報の利用が容易ではない。そこで,絶対位置6)や相対位置7),構造位置9)に基づいた位置表現を加える手法が提案されている。RGATモデルも同様に注意機構を基に構成されるため,時系列情報の利用が容易ではない。そこでIngrahamらはタンパク質の設計に際し,タンパク質の相対的な位置をGNNのエッジに付加する手法を提案した10)。
3.提案手法
対話文における感情認識の問題設定を示す。本設定では,対話文における各発話u1, u2, …, uNの感情ラベル (Neutral, Surprise, Fearなど)を認識する。ただしNは1つの対話に現れる発話の数を示す。また,1つの対話に登場する話者をsm (m=1, …, M)とする。ただしMは話者の人数を示す。
提案手法は,発話特徴量の抽出,位置表現を加えた発話関係の抽出,感情ラベルの識別の3つで構成される。全体図を2図に示す。本手法は,Ghosalらの手法5)を参考に,発話間の関係の抽出を目的として,RGATモデルを構築する。さらに,RGATでは取得困難な発話の順序情報の獲得を目的として,位置表現を加える手法を提案する。

3.1 発話特徴量の抽出
本節では,事前学習済み言語モデルBERT (Bidirectional Encoder Representations from Transformers)11)*7 を用いた発話特徴量の抽出方法12)を参考にし,発話内のトークン*8 ごとの特徴量を作成する。まず,各発話u1, u2, …, uNを事前学習モデルに合わせたトークナイザ*9 を用いて,トークンごとに分割する。発話uiの分割されたトークンを(ui,1, ui,2, …, ui,Ti)とする。ただしTiは発話uiに含まれるトークンの数を示す。次に,事前学習モデルRoBERTa-large13) *10 を用いて,発話の内容を表す特徴量を抽出する。最後に,最大値プーリングを通じて発話uiの特徴量ベクトルhi0を得る。
3.2 順序情報を考慮した発話関係の抽出
次に,3.1節で作成した特徴量hi0をRGATに入力し,発話間の関係を表す特徴量を作成する。本手法は,自己依存と相互依存を区別するために,RGATを用いて関係の種類に応じたネットワークを用意する。また,注意機構を導入し,関連性のある発話に注意を向ける。さらに,発話の順序情報の利用を目的として,依存関係の種類に応じた位置表現を加える方法を提案する。
(1)グラフ構造
RGATモデルにおけるグラフ構造を定義する。グラフのノード (発話の特徴量)をvi∈Vとし,2つのノードvi, vjの間を結ぶエッジ (発話間の関係)を(vi, r, vj )∈Eとする。ただし r∈R はエッジの種類 (依存関係の種類)を示す。ノードとエッジ,エッジの種類を一つにまとめた複数のグラフの集合を,G =(V, E, R)と定める。
(2)ノード
グラフのノードvi∈Vは,各発話の特徴量ベクトルを用いて表す。ノードviは,発話の特徴量ベクトルhi0を初期値とする。RGATを複数の層で重ねることにより,隣接する発話の特徴量を複数回集計する。L回集計した発話uiの特徴量ベクトルをhiLとする。
3.3 エッジの種類
本節では,発話間の関係ごとにグラフのエッジを構築する。Ghosalらの手法5)を参考に,(a)話者の関係と(b)時間の関係に基づきエッジの種類を決定する。
(a)話者の関係: 発話間の関係を自己依存と相互依存のいずれかに割り当てる。たとえば,話者smによる発話uiに対して,同じ話者smの発話 (uiを含む)を自己依存とする。一方で,話者smによる発話uiに対して,違う話者sk≠mの発話を相互依存とする。
(b)時間の関係: 発せられた時間によって,エッジの種類を割り当てる。すなわち発話uiに対して,発話ujが先に発せられたか (過去),または後に発せられたか (未来)に応じて種類を割り当てる。
以上より,(a)話者の関係と(b)時間の関係に基づき,(1) 自己 - 過去, (2) 相互 - 過去, (3) 自己 - 未来, そして (4) 相互 - 未来, の計4種類のエッジを設定する。エッジの種類をR={1, 2, 3, 4}とする。
次に,対話文におけるすべての発話について,上記の4種類の関係に基づいたグラフを構築する。グラフ構築の例を3図に示す。3図は,4番目の発話(a)と5番目の発話(b)を基準にしたときの,それに隣接する発話との関係を示す。例えば,3図(a)のように4番目の発話を基準にした3番目の発話は,過去の他者の発話なので,黄色で示す(2) 相互 - 過去の関係 (r=2)を表す。次に3図(b)のように,5番目の発話を基準にした3番目の発話は,過去の自分自身の発話なので,赤色で示す(1) 自己 - 過去の関係(r=1)を表す。このように,対話文におけるすべての発話uiに対して,隣接する発話ujと,話者と時間の関係に基づく4種類の関係を基にグラフを構築する。

3.4 RGAT
RGCN (Relational Graph Convolutional Network)モデル14)*11 とGAT (Graph Attention Networks)モデル15)*12 を参考に,隣接する発話の特徴量ベクトルを加味した,l+1層目の発話uiの特徴量hil+1を作成する。特徴量hil+1を作成する式を示す。
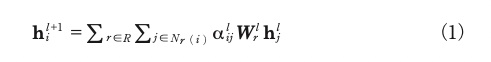
ここで、3.4(1)項に示す発話uiと発話uj間の注意機構と3.4(2)項に示す位置表現を加味した重み係数αiljにより,隣接する発話の重み付けを行う。また,エッジの種類rで隣接する発話の特徴hjlを,すべてのエッジの種類Rで集計し特徴量を得る。Nr(i)はエッジの種類rで発話uiに隣接する発話の集合を示す。Wrlはエッジの種類rごとに用意したRGATの学習可能なパラメータである。
(1)エッジの重み係数
式(1)における,注意機構を用いたエッジの重み係数αiljを本節で導入する。本手法は,GATモデル15)と同様の注意機構を利用する。ただし,発話uiはエッジの種類rごとに隣接する発話の集合Nr(i)の発話ujを持つため,エッジの種類rごとにパラメータを用意する。エッジの重み係数αiljを下式で示す。

Wrlとαrlはエッジの種類rごとに用意した注意機構の学習可能なパラメータを,· Tは転置を示す。活性化関数LeakyReLU (Leaky Rectified Linear Unit)*13 を通じて得たziljを,集合Nr(i)におけるedge softmax*14 で正規化し,重み係数αiljを得る。
(2)位置表現
本項では,RGATモデルでは取得が難しい発話の順序情報の利用を目的として,エッジの種類に応じた位置表現を新たに作成し,RGATに加える手法を提案する。提案手法の位置表現を4図に示す。
順序情報を付与する従来手法には,絶対位置6)や相対位置7)に基づく位置表現がある。4図のように,絶対位置はノード (発話)の順番に基づき,相対位置はエッジ (発話間の関係)すなわち発話から発話への相対距離に基づく。発話から発話へ有向グラフを結ぶRGATでは,相対位置を基にした位置表現の適用が望ましいと考えられる。しかしながら,相対位置を基にした位置表現は,エッジの種類を考慮せず一律に順序情報が与えられる。本手法は,自己依存と相互依存の取得を目的としてRGATを利用するため (3.4節),エッジの種類に応じた位置表現を作成する。以上より,エッジの種類ごとに区別した相対位置の位置表現を新たに作成する。4図に示す提案する位置表現をpeijとする。
また4図に示すように,相対位置に基づく提案手法は,発話から発話への相対位置に相当するため,エッジの重み係数αiljに加えることができる。新たに提案手法を加えたエッジの重み係数を下式で示す。
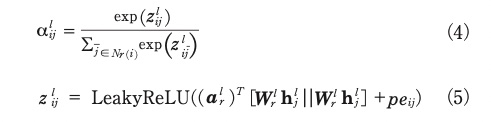
3.5 感情ラベルの識別
3.2節で発話の依存関係を考慮し作成した特徴量ベクトルhiLと,3.1節で発話の内容を抽出した特徴量ベクトルhi0を連結したベクトルxを入力し,活性化関数ReLU (Rectified Linear Unit)活性化関数*15 を挿入した2層のFFNN (Feed Forward Neural Networks)*16 を用いて,感情ラベルを識別する。式を以下に示す。
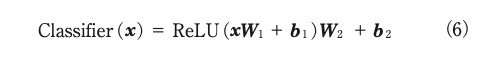
W1とW2はFFNNのパラメータを示し,b1とb2は学習可能なバイアスベクトルを示す。
4.評価実験
対話文の感情認識における3つのベンチマークセットを用いて,提案手法の認識性能を評価する。
4.1 実験条件
Train, Validation, Test*17 データの割合と各データセットの評価方法を1表に示す。また各セットにおける対話数と発話数,クラス数も示す。MELD16)は,海外ドラマFriendsの,一部シーンを切り取った英語音声の書き起こしからなるデータセットであり,1つの対話に複数の話者が登場する。各発話は,(Neutral, Happiness, Surprise, Sadness, Anger, Disgust, または Fear)の計7つのラベルのうち1つが付与される。次に,IEMOCAP17) は2人の話者が1対1で行う会話を収録し,その音声を書き起こしたデータセットである。各発話は,(Happy, Sad, Neutral, Angry, Excited, または Frustrated)の計6つのラベルのうち1つが付与される。3つ目のEmoryNLP18)はMELDと同様にTVドラマFriendsから,一部のシーンを切り取り収集したデータセットである。MELDとデータサイズとラベルの種類が異なり,(Neural, Sad, Mad, Scared, Powerful, Peaceful, または Joyful)の計7つのラベルのうち1つが付与される。Ghosalらの手法5)で用いられた評価指標を参考にし,すべてのデータセットでWeighted-F1*18 値を用いて評価する。

4.2 ベースライン手法
提案手法の有効性を検証するために,5つの従来手法と精度を比較する。DialogueRNN 4) はCNN (Convolutional Neural Networks)を用いて発話の特徴量を抽出し,各発話の関連と話者の特徴,感情の推移を,それぞれGRUでモデリングする手法である。DialogueGCN 5)はCNNを用いて発話の特徴量を抽出し,隣接する発話間の相互作用をGRUによって抽出する手法である。さらに,自己依存と相互依存の取得にRGATを利用する手法である。IEIN 19)は双方向GRUを用いて発話の特徴量を抽出し,双方向GRUと注意機構を用いて発話間の相互作用を抽出する手法である。さらに,感情ラベルの確率を入力し,新たな感情ラベルの確率を出力するネットワークを用いる。このように再帰的に確率を導出することで,隣接する発話間の影響を利用する。HiTrans 20)はEmoryNLPデータセットにおいて,世界最高峰の認識精度を達成した手法である。発話特徴量の抽出にBERTモデルを用い,話者間の関係の抽出にTransformer Encoderを利用し,階層的に組み合わせた手法である。DialogXL 21)はMELD,IEMOCAPデータセットにおいて,世界最高峰の認識精度を達成した手法である。過去の発話を保存し共有するネットワークを,XLNet 22)に加えた手法である。また隣接する発話間の関係 (local)と,会話全体の発話間の関係 (global)と,話し手,聞き手の特徴を,それぞれ自己注意機構を用いて抽出する手法である。
4.3 実験結果と考察
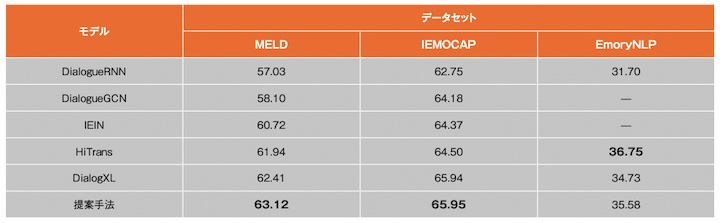
従来手法との比較結果を2表と3表に示す。提案手法を除くすべてのWeighted-F1値は,各文献から引用する。
2表より,IEMOCAPデータセットでは,Weighted-F1値65.95%を獲得し,世界最高水準の認識精度を達成した。またMELDデータセットでは,Weighted-F1値63.12%を達成し,従来手法を約0.7%近く上回る世界最高水準の認識精度を達成した。以上の結果から3つのベンチマークデータセットのうち,2つのデータセットで世界最高峰の認識精度を達成し,提案手法の有効性を確認した。さらに,複数のベンチマークで高い認識精度を有することから,データ数や発話数,登場する話者数が異なる場合でも,精度良く認識できることを確認した。
次に,MELDデータセットを用いて,感情ラベルごとの認識精度を比較する。結果を3表に示す。従来手法 (#1〜#3)に加えて,#4に発話特徴量の抽出を目的としてRoBERTaを用いた手法(RoBERTa),#5に発話関係の抽出を目的としてRGATを加えた手法(+RGAT),そして#6に位置表現を加えた提案手法(+PE)の結果を示す。
結果から,従来手法 (#1〜#3)と比較し,すべての感情ラベルで提案手法 (#4〜#6)の有効性を確認できた。特に,出現回数の少ないDisgustラベルにおいて,提案手法 (#7)はF1値27.51%を達成し,F1値19.38%を獲得したLuらの既存手法 (#3)を8%以上上回る認識精度を達成した。出現頻度の低い感情ラベルにおいても,提案手法の有効性を確認した。
またRoBERTa(#4)と+RGAT(#5)と比較し,ほとんどすべての感情ラベルで提案手法(#6)の有効性を確認できた。しかし,Fearラベルでは,RoBERTa(#4)が高い認識性能を達成した。MELDデータセットでは, “I lost it” や “How bad is this?” といった発話に,しばしばFearラベルが付与される。RoBERTa(#4)が最も高い値を獲得したことから,他の発話からの影響や順序情報に比べて,発話内容がFearの感情に影響を与えることが分かった。

5.おわりに
本論文は,対話文における各発話の感情認識において,RGATモデルに適した順序情報を加える手法を提案した。順序情報を加えたRGATを用いることで,発話間の関係と発話の順序情報の両方を利用した。3つのベンチマークデータセットを用いて実験を行ったところ,2つのデータセットで従来手法を上回る認識精度を達成し,その有効性を確認した。