テレビ映像を対象とした顔認識技術
大量に蓄積された映像データを管理するためには,所望のシーンを効率的に検索する技術が不可欠である。特に放送局においては,特定の人物が映るシーンを検索したいという要望が多くある。しかし,従来の顔認識手法は,照明条件や,顔の向き,表情などの変動によって認識精度が低下するという課題があった。そこで本稿では,テレビ映像を対象とした,画像変動に頑健な顔認識手法を提案する。本手法では,従来手法で広く利用されている特徴点ベースの画像特徴ではなく,領域ベースの新たな画像特徴を利用することで,各種変動への頑健性を向上させる。評価実験では,約150話分のドラマ番組を利用して,提案手法の有効性を検証した。また,従来手法との比較実験により,提案手法の優位性を検証した。
1.はじめに
近年,記録デバイスの大容量化や映像圧縮技術の発展により,大量の映像データを一元的に管理することが可能となっている。各家庭の録画機器の記録容量も増加しており,個人が数千時間の映像を保有することも最近では珍しくない。このような大量の映像を管理する状況においては,所望のシーンを効率的に発見するための映像検索技術が非常に重要となる。これは,映像が時間軸を持つメディアであるため,一覧性に乏しく,内容の確認に時間を要するためである。
放送局においても,過去の放送番組や取材映像が大量に保管されており,貴重な映像資産を有効活用するための検索技術が求められている。特に,番組制作者からは,特定の人物が映るシーンを素早く検索したいという要望が多くある1)。具体的には,ある俳優の過去の出演シーンを検索したいという要望や,取材映像の中から特定の人物のインタビューシーンを集めたいという要望である。しかしながら,放送局に保管されているすべての映像に,人手でメタデータ(映像の内容を説明するデータ)を付与することは現実的ではない。そこで本稿では,テレビ映像に映る俳優が誰であるかを画像解析によって自動認識する手法を提案する。
画像解析による顔認識技術については,従来からさまざまな研究が行われている。特に,セキュリティー分野における技術は高精度化が進んでおり2),すでに実用化されている例も多くある。例えば,テーマパークの入場者を顔認識によって認証する技術がある3)。入場ゲートには,カメラとモニターが内蔵されたボックス状の機器が設置され,入場者がそれをのぞき込む形で認証する。ボックス内のモニターには入場者の顔が映し出され,枠内に顔が収まるよう位置調整を促すようになっている。
顔認識における精度低下の主な要因は,撮影時の照明条件や,顔の向き,表情の変動などである。実用化されている多くのシステムでは,顔画像を撮影する際の環境を整えることでこれらの変動を抑え,認識精度の向上を図っている。また,認証に失敗した場合は,ユーザー自身がカメラへの映り方などを調整し,もう一度やり直すことが前提となっている。さらに,照明条件の変化の影響を軽減するために,近赤外カメラを利用する手法4)も提案されている。
それに対して,本研究が対象とするテレビ映像においては,照明条件や,顔の向き,表情などの変動に加えて,画質や画像解像度にも制限があるため,セキュリティー分野を対象とした既存技術をそのまま適用することは難しい。そこで本稿では,画像変動に頑健な物体認識のアプローチ5)を利用した顔認識手法を提案する。本手法では,従来の特徴点ベースの画像特徴ではなく,領域ベースの画像特徴6)を利用することで頑健性の向上を図る。また,俳優の判定には,機械学習手法の1つであるサポートベクターマシン(SVM:Support Vector Machine)*1を利用する。本手法の評価実験を実施し,実際に放送されたドラマ番組の映像を利用して有効性を検証した。
2.既存技術
既存技術の代表的なアプローチである「特徴点ベースの顔認識手法」7)8)を1図に示す。1図は,データベースに登録された顔画像と入力顔画像が同一人物かどうかを判定する処理を表す。まず始めに,平均的な顔から作成した3次元平均顔モデルを顔画像に重ねる。次に,この顔モデルを顔画像に合わせて変形させる。変形が終了したら,顔モデルの頂点に当たる点を顔特徴点として検出する。顔特徴点は,個人の差異が現れやすいと想定した位置に設定されている。その後,必要に応じて顔の向きを補正した後,顔特徴点の周辺から画像特徴を算出する。画像特徴としては,輝度の変化量や変化の方向を算出する。最後に,双方の顔画像から算出した画像特徴を比較して同一人物かどうかを判定する。
上記の既存技術における認識精度は,顔特徴点の検出精度に大きく依存している。顔特徴点が正確に検出できれば,人物間の差異が表れやすい部位を厳密に比較することが可能となり,認識精度を向上させることができる。しかし,照明条件や,顔の向き,表情などの変化が大きい場合は,顔特徴点の検出位置に誤差が生じ,個人の特徴を正確に抽出することが困難となる。

3.1 手法の概要
既存技術の課題を解決するために,本稿では,顔特徴点の検出を必要としない「領域ベースの顔認識手法」を提案する。提案手法の全体概要を2図に示す。まず,入力映像をカメラの切り替え点(カット点)で分割した後,各カットから代表フレームを抽出する。本手法では,カットの先頭のフレームを代表フレームとする単純な方法を採用した。次に,代表フレームから顔領域を検出し,一定のサイズに正規化する。続いて,正規化した顔画像から領域ベースの画像特徴ベクトルを算出する。
学習フェーズにおいては,画像特徴ベクトルを用いて,その人物らしさを判定する識別器を俳優ごとに学習する。具体的には,同一人物の顔画像から算出された特徴ベクトルの集合をSVMで解析して他人との境界を求め,これを識別器とする。
検索フェーズにおいては,人物名が未知の顔画像の特徴ベクトルを識別器に入力して,その俳優らしさを表すスコアを求めた後,スコア順に並べて検索結果とする。

3.2 画像特徴ベクトルの算出
顔画像から画像特徴ベクトルを算出する手順を3図に示す。始めに入力画像とそのエッジ検出画像*2を,細かな矩形領域に分割し,各領域から輝度の勾配に基づく特徴を算出する。提案手法では,入力画像およびエッジ検出画像に対する矩形領域のサイズを,それぞれ16×16ピクセルおよび24×24ピクセルに設定した。これらの矩形領域をさらに4×4ブロックに分割し,各ブロックにおいて8方向勾配ヒストグラム*3を算出する。これを,その矩形領域の輝度勾配特徴とする。1番目の矩形領域からN番目の矩形領域までの輝度勾配特徴は,次式で表される。

ここで,xiとdiは,それぞれi番目の矩形領域の中心座標と輝度勾配特徴を表す。diは4×4×8=128次元のベクトルとなる。以降の説明では,ベクトルを太字の記号で表記する。
次に,輝度勾配特徴diを局所制約線形符号化9)を用いて変換し,符号化特徴ベクトルviに変換する。局所制約線形符号化は,入力ベクトルをC個の基底ベクトルの重み付き和で表現する手法であり,分類が容易となるように入力ベクトルを変換する目的で使用する。基底ベクトルは,十分な数の顔画像データから求めた輝度勾配特徴diをC個のクラスに分類し,各クラスの重心ベクトルを求めることで得る。提案手法ではC=2,048に設定した。符号化特徴ベクトルviの次元は2,048となる。
続いて,座標xiのK近傍*4の矩形領域における符号化特徴ベクトルvi(k)(k=1,…,K)を,(2)式に示す重み付き最大プーリングを用いて統合し,ɡiを求める。提案手法ではK=20に設定した。このように周辺情報を統合することにより,表情変化などへの頑健性を向上させることができる。

ここで,maxはベクトルの要素ごとに最大値を選択する演算を表す。またskは,xiからの距離に基づく重みを表し,次式で定義する。
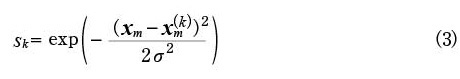
σは重みを調整するパラメーターである。また,xm(k)は座標xiのK近傍の矩形領域の中心座標を表し,xmは(1)式と同様にm番目の矩形領域の中心座標を表す。
その後,入力顔画像をM個の矩形領域に改めて分割し,領域ごとにɡiを集計することで,各領域に対応する特徴ベクトルhj(j=1,…,M)を求める。提案手法ではM=16とした。hjの算出式は次のとおりである。

ここで,rj(j=1,…,M)は入力顔画像におけるj番目の矩形領域を表す。また,wiは座標xiにおけるエッジ強度*5に基づいて定義された重みを表す。具体的には,入力画像のエッジ検出画像にガウシアンフィルター*6を適用して生成した重みマップを利用する。これにより,エッジが密集した領域の特徴は重みが大きくなり,エッジが少ない平坦な領域は重みが小さくなる。この処理により,元の顔画像における位置情報を最終的な画像特徴ベクトルに反映させることができる。最後に,すべてのhjを連結して「顔画像全体の画像特徴ベクトル」とする。このベクトルの次元はC×M=32,768となり,これをSVMの学習に利用する。

4.評価実験
実際のドラマ番組を用いて提案手法の有効性を検証した。実験には,2013年にNHKで放送された「連続テレビ小説 あまちゃん」全156話(1話あたり15分)を使用した。実験映像の解像度は432×240ピクセルである。実験映像からは合計41,269カットが検出された。各カットから64×64ピクセル以上の顔領域を検出し,それらを64×64ピクセルに正規化した。顔領域の検出には既存手法10)を利用した。検出された顔領域は合計で12,566個であった。その中から10%(約1,300個)を無作為に抽出してSVMの学習データとし,残りを評価データとして利用した。学習データに5回以上出現した17名の俳優を認識対象とし,それぞれについて識別器を学習した。それ以外の俳優については,学習データ数が十分に得られないため,信頼性のある評価データが得られないと判断した。
実験で認識対象とした17名の俳優の年齢や性別などを1表に示す。17名のうち,10名が男性,7名が女性であり,年齢は17歳から68歳まで分布している。実験に使用した番組は,一般的なドラマと比較して,俳優の表情の変化や,顔の向きの変動が大きい演出となっている。撮影場所や撮影時間,照明条件もさまざまである。テストデータにおける赤(R),緑(G),青(B)の画素値の変動を表す標準偏差は20前後,顔の向きの変化は約±60°であった。
| 俳優 | 性別 | 年齢 | 備考 |
|---|---|---|---|
| A | 女性 | 50 | |
| B | 男性 | 39 | 坊主頭 |
| C | 男性 | 47 | 眼鏡 |
| D | 男性 | 47 | |
| E | 女性 | 48 | |
| F | 男性 | 19 | |
| G | 男性 | 65 | 眼鏡 |
| H | 男性 | 29 | 眼鏡 |
| I | 男性 | 27 | |
| J | 女性 | 17 | |
| K | 男性 | 68 | |
| L | 男性 | 47 | |
| M | 女性 | 19 | |
| N | 女性 | 68 | |
| O | 女性 | 47 | |
| P | 男性 | 68 | 口ひげ |
| Q | 女性 | 48 |
4.1 検索精度の評価
始めに17名の俳優に対する検索精度を評価した。評価指標には,検索結果の上位n件(各俳優について,その俳優が映っていると判定された評価データのうち,スコアが上位のn件)の平均適合率AP(n)を用いた。AP(n)は,次式で表される。

ここで,δiは検索結果のスコアが第i位の結果が正解であれば1,不正解であれば0を表す。平均適合率AP(n)は,検索結果における誤りの少なさを表す指標であり,数値が大きいほど検索精度が高いことを表し,上位に正解が集中するほど高い値となる。
検索精度の評価結果を2表に示す。実験の結果,平均適合率の全俳優についての平均(MAP:Mean Average Precision)は,上位50件が98.2%,上位100件が96.6%,上位300件が90.3%,上位500件が87.6%となった。実験映像には,照明条件や,顔の向き,表情などの大きな変化が含まれていたが,非常に良好な結果を得ることができた。特に,上位50件の平均適合率については,俳優A,俳優D,俳優Pを除くすべての俳優が100%という結果となった。
俳優ごとの精度については,学習データ数が多いほど精度が高くなる傾向が見られた。特に学習データが多かった俳優Mと俳優Oについては,上位50件,100件,300件,500件の平均適合率がすべて100%となった。また,学習データが50件以上となった俳優Cと俳優H,俳優Jについても,上位500件の平均適合率が97%以上という非常に高い精度が得られた。一方,学習データが少なかった俳優Aと俳優Pについては,上位500件の平均適合率が70%以下に低下する結果となった。少ない学習データからは,俳優の特徴を十分に捉えられなかったものと考えられる。しかし,同様に学習データが少なかった俳優Gと俳優Kについては,上位50件,100件,300件,500件の平均適合率がすべて90%以上となる精度が得られており,学習データの内容や俳優の違いによって,精度にばらつきが出ることが分かった。今後,より多くの番組や俳優を対象とした実験を実施し,提案手法の特性を詳細に分析する必要がある。
| 俳優 | 学習データ数 | 平均適合率(上位n件) | |||
|---|---|---|---|---|---|
| 50件 | 100件 | 300件 | 500件 | ||
| A | 6 | 0.906 | 0.874 | 0.732 | 0.693 |
| B | 22 | 1.000 | 0.990 | 0.906 | 0.884 |
| C | 51 | 1.000 | 1.000 | 0.997 | 0.989 |
| D | 18 | 0.984 | 0.944 | 0.802 | 0.727 |
| E | 15 | 1.000 | 0.960 | 0.841 | 0.783 |
| F | 15 | 1.000 | 0.980 | 0.846 | 0.813 |
| G | 7 | 1.000 | 0.974 | 0.943 | 0.926 |
| H | 62 | 1.000 | 1.000 | 1.000 | 0.999 |
| I | 17 | 1.000 | 0.999 | 0.910 | 0.881 |
| J | 61 | 1.000 | 1.000 | 0.991 | 0.970 |
| K | 10 | 1.000 | 0.978 | 0.915 | 0.901 |
| L | 43 | 1.000 | 1.000 | 0.948 | 0.915 |
| M | 288 | 1.000 | 1.000 | 1.000 | 1.000 |
| N | 29 | 1.000 | 1.000 | 0.954 | 0.915 |
| O | 165 | 1.000 | 1.000 | 1.000 | 1.000 |
| P | 8 | 0.809 | 0.723 | 0.569 | 0.515 |
| Q | 53 | 1.000 | 1.000 | 0.998 | 0.978 |
| 平均(MAP) | 0.982 | 0.966 | 0.903 | 0.876 | |
4.2 既存手法との比較
提案手法の優位性を検証するために,既存手法との比較実験を実施した。既存手法として,代表的な4手法(Clippingdale20128),Turk199111),Belhumeur199712),Ahonen200613))を選択した。実験結果を4図に示す。上位500件のMAPで比較すると,提案手法は87.6%となり最も高い結果となった。続いて,Ahonen2006が51.7%,Turk1991とClippingdale2012が40.3%という結果となり,最も低い結果となったのはBelhumeur1997の22.2%であった。この結果から,既存手法をドラマ番組にそのまま適用しても,十分な精度が得られないことが実験的に確認された。いずれの既存手法も,ドラマ番組における画像変動への頑健性が不足し,精度低下につながったものと考えられる。

4.3 再現率と適合率による評価
前節までの平均適合率による評価では,検索結果における検索漏れは考慮されていない。そこで,提案手法の検索漏れと検索誤りを統合的に評価するため,再現率と適合率を指標とした評価を実施した。再現率,適合率の定義は以下のとおりである。


再現率は検索漏れの少なさ,適合率は検索誤りの少なさを表す指標である。いずれも数値が大きいほど精度が高いことを表す。なお,再現率と適合率はトレードオフの関係にある。
俳優Aと俳優Cに対する評価結果を5図に示す。これらの俳優は,平均適合率による評価において,検索精度が低かった俳優と高かった俳優のそれぞれから選択した。グラフの横軸が再現率,縦軸が適合率を表し,右上に近いほど精度が高いことを表す。全体的に,俳優Aよりも俳優Cの精度が高いことが分かる。再現率と適合率が同程度となる部分を評価すると,俳優Cは再現率,適合率が90%程度となった。検索漏れ,検索誤りともに10%程度に抑えられており,高い検索精度が達成できたものと考える。一方,俳優Aについては,再現率,適合率が70%程度となった。精度低下の一因としては,学習データ数の不足が考えられる。今後,画像変換によって人工的に生成した画像データを学習データに追加するなど,俳優によらず高い精度が得られるような方策を検討する必要がある。

5.おわりに
本稿では,画像解析を利用した顔認識手法を提案した。提案手法では,テレビ番組における照明条件や,顔の向き,表情などの変動に対する頑健性を高めるために,従来の特徴点ベースの画像特徴ではなく,領域ベースの新たな画像特徴を考案した。
実際に放送されたドラマ番組を用いた評価実験では,俳優17名に対する検索結果の平均適合率の平均が,上位50件で98.2%,上位100件で96.6%,上位300件で90.3%,上位500件で87.6%という良好な結果が得られた。
今後は,実験データを増やして提案手法を詳細に評価するとともに,ドラマ以外の番組への適用についても検討を進めたい。また,学習データを人工的に合成する仕組みや,顔軌跡のような動画像特徴の利用,深層学習の利用などについても検討したい。
本稿は,IEEJ Transactions on Electrical and Electronic Engineering(電気学会共通英文論文誌)に掲載された以下の論文を元に加筆・修正したものである。
Y. Kawai, T. Mochizuki and M. Sano:“Recognizing Persons in Television Programs using Region-based Image Features,” Vol.13,No.9,pp.1348-1356(2018)