音声合成技術の動向と放送・通信分野における応用展開
最近,機械による合成音声を耳にする機会が増えてきた。電話の自動応答,公共交通機関や自治体のアナウンス,パソコンやスマートフォン上のアプリによる情報の読み上げなど,音声合成は多様な分野に導入されている。本稿では,テキストとその発話を大規模に集めてデータベース化した「音声コーパス」を利用して,汎用的に任意のテキストを音声に変換する音声合成方式を中心に技術の動向を概説するとともに,NHKが取り組んでいる「効率的な番組制作」や「人にやさしい放送技術」を目的とした音声合成技術の開発と,放送・通信分野における音声合成技術の応用展開について紹介する。
1.はじめに
音声合成は音声認識とともに,人と機械とのユーザーインターフェースに有用な要素技術である。音声合成方式は,人が声を発する仕組みを模倣する機械的な方式に端を発し,コンピューター技術の発展に伴い,数値データで表現された情報や任意のテキストを電子的に読み上げる方式へと進化してきた。音声合成を用いることにより,人が情報を読み上げる作業を省力化できることから,さまざまな分野への導入が進められている。ここでは,まず1図に沿って,音声合成方式の分類例を概説する。
限定された内容で高品質な読み上げが必要な場合は,文節程度の単位で録音した音声を組み合わせて再生する「録音編集方式」が主に利用されている。一方,汎用的に任意のテキストを読み上げる必要がある場合は,単語より短い単位で音声を扱う「テキスト音声合成方式」が用いられる。
テキスト音声合成方式として,1990年代を中心に,音声合成分野の専門家による音響的・言語的知見(規則)に基づいて音声波形を合成する「規則合成方式」が実用化されてきたが,近年,コンピューターの処理速度の高速化,低廉化,人工知能*1 や機械学習*2 などの技術の進展に伴い,テキストとその発話を大規模に集めてデータベース化した「音声コーパス」を利用する「コーパスベース合成方式」の高品質化および多様化が進められている。この方式は,主に波形を生成する手法の違いにより,音声コーパスから選択された音声波形を接続する「波形接続型合成方式」と,音声波形の音響的な特徴に関して事前に機械学習で求めた統計モデル*3 を用いて音声波形を合成する「統計モデル型合成方式」の2つに大別できる。
本稿では,音声合成技術の動向と応用展開について解説する。コーパスベース合成方式として,2章では波形接続型合成方式,3章では統計モデル型合成方式,4章では上記2方式を組み合わせた「ハイブリッド方式」について概説し,5章では放送・通信分野における音声合成技術の利用例について紹介する。

2.波形接続型合成方式1)2)3)
波形接続型合成方式は,音声合成システム内に音声コーパスから構築した音声波形のデータベースを保持しておき,そこから合成対象のテキストに対応する音声波形を選択し,接続することにより合成音を生成する。
2.1 処理の流れ
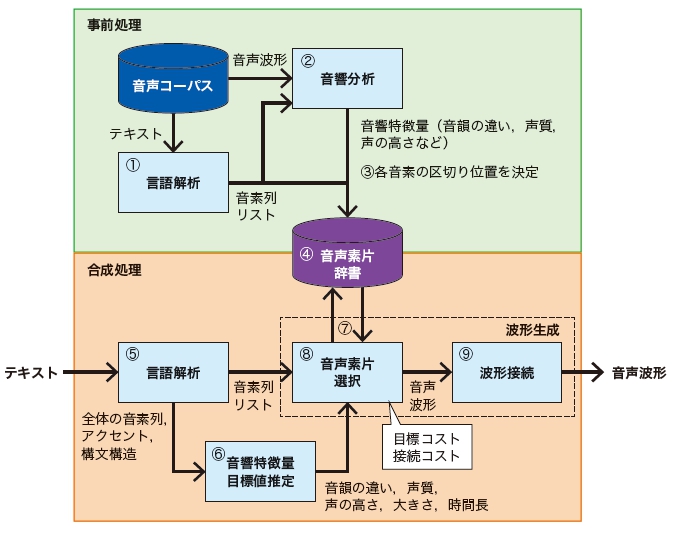
2図に波形接続型合成方式の概略を示す。
事前処理では,①音声コーパスに含まれるテキストを言語解析し,音声コーパスに出現するすべての音素*4 の並び(音素列)を列挙し,音素列リストを作成する。②音声コーパスを構成する音声波形を25msの時間長のフレームで5msごとにずらして切り出して音響分析し,フレームごとに音韻*5 の違い,声質,声の高さなどに関するパラメーターである音響特徴量を求める。③音声認識の技術を利用して,音声波形におけるテキストの各音素の区切り位置を自動的に決定する。④音素列ごとに,その区切り位置,音響特徴量と併せて,さまざまな長さを取りうる音声合成単位の波形を音声素片として「音声素片辞書」に登録しておく。
合成処理では,⑤合成対象のテキストを言語解析し,テキストに出現するすべての音素列を列挙し,音素列リストを作成するとともに,テキスト全体の音素列,アクセント,および構文構造*6 の情報を求める。⑥テキスト全体の音素列,アクセント,および構文構造の情報から,学習データや専門家の音響的・言語的知見を利用して事前に構築した規則もしくはモデルに基づいて,音響特徴量の目標値(音韻の違い,声質,声の高さ,大きさ,時間長)を推定する。⑦音素列リストに基づき,音声素片辞書から音素列に合致する音声素片を接続候補として列挙する。⑧音響特徴量の目標値と各音声素片の接続候補の音響特徴量を利用して,接続したときの連続性(接続コスト),音響特徴量の目標値との一致度(目標コスト)を評価尺度として,動的計画法*7 によって最適となる組み合わせを探索し,音声素片を選択する。⑨選択された音声素片を接続し合成音声を出力する。
2.2 波形接続型合成方式の特徴と動向
一般的に,音声コーパスの規模が大きくなるほど,未知のテキストの合成に必要な音声素片をカバーできる可能性が増す。また,接続箇所が少ないほど,音声コーパス中の連続した音声データが利用され,実際の発話に匹敵する肉声感の高い合成音が得られる。音声素片どうしの接続がうまくいかない場合には,音質劣化が目立つ傾向がある。また,合成音の音質は,音声コーパスとして録音した発話と同じ話者,口調や感情表現などの発話様式に限られるため,多様な話者,発話様式を実現するには相応の大規模な音声コーパスを用意する必要がある。
波形接続型合成方式は1990年代前半から2000年代前半にかけて,音声コーパスの構築方法,音響特徴量の目標値推定方法,評価尺度の設定方法,音声素片長の決定方法,音声素片接続候補の探索方法など,多岐にわたって研究がなされ,現在,市販されている音声合成システムの大勢を占める。これらの研究の過程で,3章で解説する統計モデル型合成方式と組み合わせたハイブリッド方式(4章で解説)も提案された。
3.統計モデル型合成方式
統計モデル型合成方式では,事前に音声コーパスを構成する音声波形の音響特徴量を,隠れマルコフモデル(HMM:Hidden Markov Model)*8 やディープニューラルネットワーク(DNN:Deep Neural Network)*9 などの機械学習の手法でモデル化し,音声合成システム内に保持しておく。合成時に,学習した統計モデルから所望のテキストに対応する音響特徴量を持つ系列を生成し,これに基づいて音声を合成する。
3.1 処理の流れ
3図に統計モデル型合成方式の概略を示す。
事前処理では,①音声コーパスに含まれるテキストを発話ごとに言語解析し,発話中のテキストの音素ごとに,前後の音素,アクセントの位置,品詞,発話中の位置などの特徴から成る「言語特徴量」を求める。波形接続型合成方式と同様に,②音声コーパスを構成する音声波形を音響分析し,フレームごとに音響特徴量を求め,③音声認識の技術を利用して,音声波形におけるテキストの各音素の区切り位置を自動的に決定する。④言語特徴量,音響特徴量,および音素区切り位置を用いて機械学習を行い,言語特徴量を入力として音響特徴量を生成する「統計モデル辞書」を作成する。
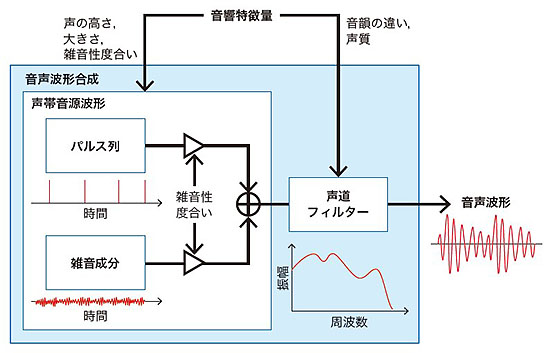
合成処理では,まず,⑤合成対象のテキストを言語解析し,音素ごとに言語特徴量を求める。⑥統計モデル辞書と言語特徴量に基づいて,音素ごとに時間長を推定し,その時間長に相当するフレーム数分の音響特徴量の系列を生成する。⑦生成された音響特徴量に基づいて,音韻の違いや声質を表現する「声道フィルター」と,声の高さ・大きさ・雑音性度合いの時間変化を表現する「声帯音源波形」を生成し,⑧声帯音源波形で声道フィルターを駆動することにより,音声波形を合成する。音響特徴量から音声波形を合成する過程を4図に示す。
機械学習により統計モデル辞書を作成する手法について,以下で説明する。

(1)HMMによるモデル化4)5)
3図の機械学習の手法としてHMMを用いる場合,学習データに対して,音素ごとに言語特徴量の違いを考慮して統計モデルを作成するが,任意の入力テキストの合成で必要な,あらゆる言語特徴量の組み合わせをカバーすることはできない。そこで,言語特徴量を構成する情報に基づいて,音響的な特徴が類似する音素は同じ統計モデルを利用するように,自動的にグループへと分類する。この方法によって,学習データに存在しない言語特徴量を持つ音素についても,統計モデルを利用して音声を合成することが可能となった。このようにHMMによるモデル化における統計モデル辞書は,グループ数分の統計モデルで構成される。しかしながら,より複雑な言語特徴量の違いを表現するには,大規模な分類が必要となる。その場合,細分化によって必然的に個々のグループに含まれる学習データ量が少なくなり,少量のデータで個々のグループをモデル化することになるため,未知のデータに対して音質劣化を招くことになる。これらの問題を解決するために,DNNが導入された。
(2)DNNによるモデル化6)7)
機械学習の手法としてDNNを用いる場合,言語特徴量の系列を入力として,対応する音響特徴量の系列を出力するように,ニューラルネットワークを学習する。DNNによるモデル化における統計モデル辞書は,ニューラルネットワークそのもので構成される。DNNの構造としては,多層パーセプトロン*10,積層自己符号化器,再帰型ニューラルネットワークなど,さまざまなものが試されている。5図にDNNによるモデル化を用いた音声合成の処理例を示す。
5図では,あらかじめ学習用の音声コーパスから,音素ごとに抽出した「音素レベル言語特徴量」と音素時間長の対を利用して時間長DNNを学習しておく。また,5ms単位のフレームごとに抽出した「フレームレベル言語特徴量」と音響特徴量の系列の対を利用して音響特徴量DNNを学習しておく。時間長DNNは,音素レベル言語特徴量をニューラルネットワークに入力したときの出力と,対応する音素時間長の値との平均二乗誤差が最小となるように学習を行うDNNである。また,音響特徴量DNNは,フレームレベル言語特徴量をニューラルネットワークに入力したときの出力と,対応する音響特徴量の値との平均二乗誤差が最小となるように学習を行うDNNである。時間長DNN,音響特徴量DNNともに,それぞれニューラルネットワークを構成する重み*11 を最適化する。最適化には確率的勾配降下法*12 に基づく誤差逆伝播アルゴリズム*13 などが用いられる。
合成時には,5図に示すように,合成対象のテキストから音素レベル言語特徴量を求め,これを時間長DNNに入力したときの出力として音素時間長が求まる。この音素時間長に基づいて,フレームレベル言語特徴量を求め,これを音響特徴量DNNに入力したときの出力として音響特徴量が求まる。この音響特徴量を用いて,4図に示す過程により音声波形を合成する。
DNNによるモデル化は,HMMによるモデル化と比べて学習に膨大な量のデータが必要となるが,HMMのように分類された個々のグループに含まれる少量のデータでモデル化するのとは異なり,すべてのフレームのデータを利用してすべての重みを最適化するため,未知のデータに対しても良好な合成音が得られることが報告されている。

3.2 統計モデル型合成方式の特徴と動向
統計モデル型合成方式は,音声波形から算出した音響特徴量を機械学習の手法によりモデル化して利用するため,波形接続型合成方式に比べて,音声合成システム内に保持するデータ容量が小規模で実現できる。音声認識で培われた,不特定話者の音響特徴量から求めた統計モデルを特定話者の発話の音声認識性能が向上するように適応させる技術を活用することにより,少ない音声データで,誰がどのような口調で話すかを表す話者性や発話様式を変更することができる8)9)。また,複数の音声コーパスから求めた統計モデルを用いて,音声コーパス間で対応する統計モデルを任意の割合で重み付け加算して使うことにより,音声コーパスには存在しない新たな音声で合成することができる10)。さらに,機械学習で作成した統計モデルを利用して,連続的に音声波形を合成するので,突発的に音質劣化が生じることがない。
一方で,音声波形をモデル化して扱うことにより,音声波形の自然なゆらぎ成分が過度に平滑化されて不自然な合成音になる。合成音の音質は,学習時に音声波形から音響特徴量を求める分析技術,ならびに,合成時に音響特徴量から音声波形を求める合成技術に依存し,音声の情報をいったん音響特徴量に圧縮して扱うため,鼻にかかったようなくぐもった音質になりがちである。
機械学習にHMMを利用する方式については,オープンソースのツールキット11)が公開されていることもあり,1990年代後半に提案されてから現在に至るまで,HMMのアルゴリズムやモデルの学習方法,モデルの適応化方法など,広く研究が進められている。最近では,携帯端末アプリへの実装が始まるとともに,モデルを適応させる技術を感情表現に利用した市販品が出始めている。
一方,単層構造のニューラルネットワークを利用する発想は1990年代に遡るが,近年のコンピューターの処理速度の高速化と低廉化,学習データの大容量化,機械学習などの技術の進展によって多層構造を持つニューラルネットワーク(DNN)の利用が実現可能となり,現在,盛んに研究が進められている。演算量は膨大になるが,言語特徴量から音響特徴量を推定する代わりに,直接音声波形を推定する方式も提案されている12)。DNNを利用する方式はHMMを利用する方式と比べて,言語特徴量を構成する要素の複雑な組み合わせを表現することができ,音質の向上が確認されている。しかしながら,他の分野と同様に,DNNを利用して良好な結果を出すには,学習データの質と量が重要であり,学習には膨大な量のデータと相応の時間が必要となる。
4.ハイブリッド方式
波形接続型合成方式と統計モデル型合成方式の,それぞれの持つ課題を解決するために,要素技術を組み合わせたハイブリッド方式としてさまざまな手法が提案されている。ここでは,波形接続型合成方式における課題を解決する,ハイブリッド方式のいくつかの方向性を紹介する
- 音声素片の分類13)
音声素片探索処理を高速化するために,HMMによる統計モデルの学習と同様に,事前に音響的な特徴が類似する音声素片をグループに分類して利用する。 - 音響特徴量の目標値推定14)15)
音声コーパスに応じて音響特徴量の目標値の推定精度を向上させるために,あるいは音声素片を探索する際の評価尺度値を算出するために,HMM統計モデルを利用する。 - 音声素片の接続平滑化16)
音声素片の接続点におけるスペクトルの不連続の度合いを減らすために,HMM統計モデルから求めた音響特徴量を利用して平滑化する。 - 音声素片と生成音声の切り替え17)
音声素片接続時の不連続の度合いを減らすために,選択した音声素片に対して,統計モデル型合成方式による音声波形も生成し,評価尺度に基づいて,滑らかに接続できる方式の音声波形に切り替えて接続する。
いずれの手法も個々に着目した課題を解決するものだが,最善とされる手法はいまだに存在せず,要素技術の最適な組み合わせが模索されている。
5.放送・通信分野における音声合成技術の応用展開
コンピューターや通信インフラの高速化・大容量化と音声合成技術の進展に伴い,1990年ごろから,放送や通信の分野においても音声合成の利用場面が広がってきた。
放送分野では,天気予報18)19),交通情報20),地震・津波速報21) など,適用範囲を限定した情報伝達に利用されることが多く,高品質な音声が求められるため,主に録音編集方式が使われてきた。一方で,汎用的に任意のテキストを読み上げるテキスト音声合成方式は,波形接続型合成方式の実用化に伴い,明瞭性のみならず肉声感が増したこともあり,微妙に非人間的な不自然さを意図した演出効果として,現在でもバラエティー番組のナレーションなどで利用されている。また,民放のテレビ放送における天気予報や,FMラジオ放送におけるニュース読み上げ,短波ラジオ放送における株価情報の読み上げにテキスト音声合成方式が利用された事例もある。
通信分野においては,パソコンやスマートフォンなどの端末上のアプリから送られた要求に応じて,クラウドサービス*14 としてサーバー側で合成音を作成し,配信するサービスが実現されている。この仕組みは,任意のテキストの合成音を作成・提供するサービス,各社のWEBサイトの情報や新聞記事の読み上げサービスのほか,音声認識技術・多言語翻訳技術と音声合成技術を組み合わせた多言語音声翻訳アプリによる実証実験にも使われている22)。また,スマートフォンのインターフェースにおける情報提示手段にも音声合成が活用されている。
一般的に,大規模コーパスを利用する波形接続型合成方式はサーバー側で処理され,小規模のパラメーターで実装可能な統計モデル型合成方式は端末側で処理される。現在,波形接続型合成方式が市販品の大勢を占めるが,少量の音声収録で特定の話者の音声合成を実現するサービスや,感情表現が可能な音声合成において,統計モデル型合成方式を利用した製品が出始めた。
NHKにおいては,波形接続型の数値音声合成*15 と録音編集方式を組み合わせた音声合成システムを開発し23),2010年度からラジオ第2放送の「株式市況」において株価を合成音声で読み上げている。また,同じく「気象通報」において,風向き,風力,天気,気圧,気温など,定型の文章パターンの組み合わせをすべてカバー可能な音声コーパスを構築し,合成時にその中から適切な組み合わせを選択する音声合成システムを開発した24)。このシステムについては,2016年度から合成音声による自動放送が始まっている。これらの音声合成システムは放送波での利用を念頭に,適用範囲を限定して高品質な合成音声を実現したものである。現在,「解説放送*16」を補完する新たな視覚障害者サービスとして,スポーツを題材とした「音声ガイドシステム」に関する研究を進めており25),その中で,任意のテキストの発話を目指して適用範囲を拡張した汎用的な音声合成技術の開発に取り組んでいる。
6.おわりに
本稿では,コーパスベース合成方式を中心に,音声合成技術の動向と応用展開について紹介した。本稿で紹介した音声合成技術は,波形接続型合成方式と,統計モデル型合成方式の2つに大別できる。波形接続型合成方式は,肉声感が高いが,音声コーパスに含まれないテキストを合成する場合,接続する波形の不連続による音質劣化が目立つ傾向にある。統計モデル型合成方式は,変化が滑らかで連続性の高い合成が可能だが,肉声感が低く機械的な音質になりがちである。現時点では,波形接続型合成方式が市販品の大半を占めるが,合成音声に要求される条件に応じて,各方式の特質を生かせるような使い分けが肝要である。両方式の特質を踏まえた高品質なコーパスベースの音声合成方式を実現することが,今後の重要な課題である。
将来,コンピューターや通信インフラの高速化・大容量化が更に進み,多様で大規模な音声コーパスを低コストで収集・処理できるようになれば,放送・通信分野に限らず,さまざまな場面において,人の発声と区別できないほど高品質で,かつ,多様な表現が可能な音声合成が活用できるようになると期待される。