対談音声認識のための話者ダイアライゼーション
話者ダイアライゼーションとは,音声から「いつ,誰が発話したのか」を推定する技術である。話者を推定することができれば,話者適応化技術により音声認識率の改善が期待できる。本稿では,対談番組のような連続した音声に複数の話者が含まれる状況において,話者交代点を検出しつつ低遅延で話者を判定する手法を提案する。提案手法では,音素情報に基づいて音声区間を分類したマルチ音素クラスのベイズ情報量基準を用いることで,話者ダイアライゼーションの精度の向上を図った。報道系情報番組の対談部分を対象とした話者ダイアライゼーション実験を行った結果,遅れ時間2秒で話者判定するタスクにおいて,話者ダイアライゼーション誤りを従来手法に比べて20.0%削減することができた。この提案手法による話者判定結果を利用した音声認識の話者適応実験では,話者交代点前後の発話に関して7.8%の単語誤り削減率を得た。
1.まえがき
本稿では,対談音声をリアルタイムで音声認識するための新たな話者ダイアライゼーションの手法を提案する。話者ダイアライゼーションとは,音声から「いつ,誰が発話したのか」を推定する技術である。音素*1 ごとの声の特徴を表す音響モデルは話者ごとに異なるため,音声から話者を推定し,その話者に適応した音響モデルを利用することで,音声認識精度の改善が期待できる1)。NHKでは,生放送番組の字幕制作を目的とした音声認識の研究を行っているが2),対談音声の認識精度が改善されれば,音声認識技術が適用可能な番組ジャンルを拡大することができる。また,番組の発話内容の書き起こしだけでなく,話者名や話者の交代点を抽出できれば,番組の検索やメタデータ*2 の制作も効率化できる3)。
本稿の話者ダイアライゼーションでは,時々刻々と入力される音声から,すでに発話したどの話者なのか,それとも新たな話者なのかを,ベイズ情報量基準(Bayesian Information Criterion:BIC)(後述)を用いて判定する4)5)。本稿で対象とする対談音声を話者ダイアライゼーションする際には,連続した音声内の話者交代点を探索しながらリアルタイムで話者の判定をする必要がある。また,判定結果の話者情報を利用して音響モデルの話者適応を行い,リアルタイムで音声を認識するためには,できる限り短い遅れ時間で精度良く話者を判定することも必要である。そこで本研究では,BICに基づいて発話内の話者交代点を検出しながら話者判定する手法の改善を目指して,発話内容の母音や子音など音素の情報を利用した手法を提案する6)。
話者ダイアライゼーションは,個人性をより多く含む音声区間を用いることで,その精度向上が期待される。聴取による話者識別実験では,母音や鼻音が識別に有効であるという報告があり7),音素情報を基に音声区間を分類することで,より高精度な話者判定が期待できる。提案手法では,入力音声を音素認識8)して得られる音素情報を用いて,音声区間を,特徴が近い音素をまとめた音素クラスに分類し,BICによる判定時にそれぞれの音素クラスで得られた判定結果を統合する「マルチ音素クラス」モデルを用いる。この提案手法の「マルチ音素クラス」モデルを用いることで,短い音声区間でも高精度な話者交代点検出と話者判定の実現が期待できる。
本稿では,話者ダイアライゼーション実験において,音声区間を音素クラスに分類しない従来手法と,音素クラスに分類した「マルチ音素クラス」による手法とのダイアライゼーション性能を比較する。また,提案手法により低遅延で得られる話者情報を利用して音声認識の話者適応を行う手法を提案し9),音声認識実験により,話者ダイアライゼーションの精度向上が音声認識の精度向上につながることを示す。
2. 提案システムの概要
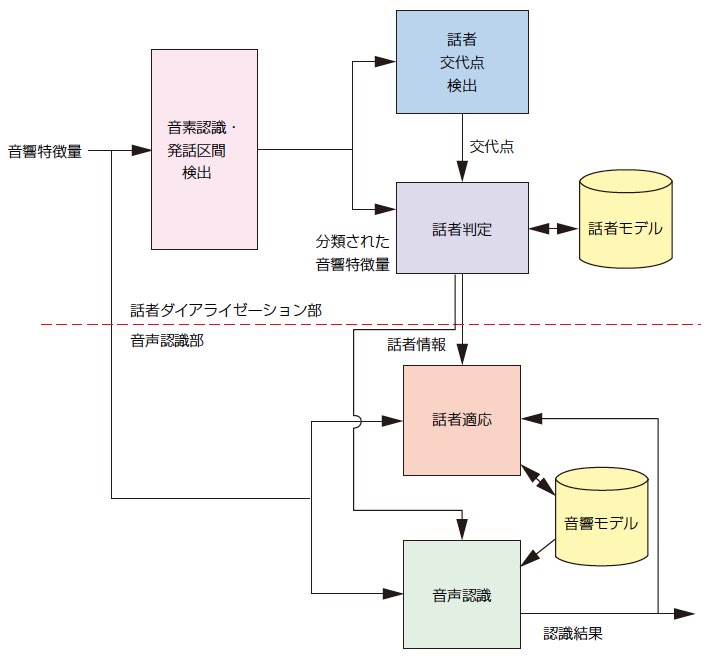
本提案手法の概要を1図にブロック図で示す。話者ダイアライゼーション部は,音声認識と同様に,12次のメル周波数ケプストラム係数(Mel Frequency Cepstral Coefficient:MFCC)*3,対数パワー*4,またそれぞれを時間方向に直線近似したときの傾き,およびその傾きの時間変化の計39次の音響特徴量を時系列に並べた,特徴ベクトル列を用いて話者の判定を行う。提案手法では,音素認識により得られる音素情報を基に,1表に示すように,個人性情報をより多く含むと考えられる「母音+鼻音」と,それ以外の「子音」のクラスに音響特徴量を分類する。本提案手法では,これら2つのクラスで構成される「マルチ音素クラス」の音響特徴量の特徴ベクトル列を用いて,BIC基準により話者の交代点を検出しつつ,登録されたどの話者による発話かを判定する。話者の判定は,話者ごとの特徴量の分布をモデル化した話者モデルを用いて行う。この話者モデルは,システムの動作開始時にあらかじめ登録しておく必要はなく,話者交代点が検出されるごとに,交代点以前の音声から後述の手順により作成または更新される。入力音声の話者が過去に発話した話者以外の新規話者と判定された場合は,新規話者モデルを作成する。それに対し,過去に発話した話者のいずれかと判定された場合には,該当の話者モデルを入力音声から再学習して更新する。ただし,対談番組のキャスターなど,事前に番組出演することが分かっていて,十分な音声データが得られる話者については,あらかじめ話者モデルを作成しておくことも可能である。
音声認識は,話者判定により得られる話者情報に従って,音響モデルを切り替えて行う。音響モデルは,話者ダイアライゼーションの話者モデルと同様,話者交代ごとに話者交代以前の音声と認識結果を用いて適応化する。この適応化した音響モデルは,次にその話者が発話したと話者ダイアライゼーションにより判定された際に音声認識で利用する。
| 母音+鼻音 | a, a:, i, i:, u, u:, e, e:, o, o:, n, ny, m, my, N |
|---|---|
| 子音 | b, by, ch, d, dy, f, g, gy, h, hy, j, k, ky, p, py, r, ry, s, sh, t, ts, w, y, z |
3. 対談番組の話者ダイアライゼーション
3.1 マルチ音素クラスのベイズ情報量基準
話者交代点の検出,および話者の判定には,共にBICに基づくΔBIC10)11)12)を用いる。ΔBICは2つの音声区間の特徴ベクトル列x,y に対して,それらが同一話者によるものかどうかを判定する基準であり,以下の(1)式および(2)式で表される。
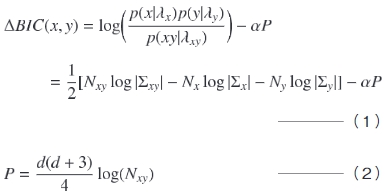
ここで,λx=(Nx, Σx)とλy=(Ny, Σy)はそれぞれ2つの音声区間xとyの特徴量の分布モデルを示す。NxとNyは各音声区間の音声フレーム数,ΣxとΣyは各特徴ベクトル列の共分散行列*5 である。λxy=(Nxy, Σxy)は2つの音声区間xとyを時間方向に連結した区間x yの特徴量の分布モデルを示し,Nxyは同区間の音声フレーム数Nx+Ny, Σxyはx yの特徴ベクトル列の共分散行列である。αは(2)式で表されるPの重み係数であり,雑音などの環境の異なる音声区間を正しく話者判定するためのマージンである。dは特徴ベクトルの次元数である。ΔBICの値が正のとき,xとyは別話者による発話であると判定される。
音響特徴量を音素クラスに分類しない(1)式および(2)式の従来手法に対して,本稿では,複数の音素クラスでの判定結果を統合できるように拡張した(3)式および(4)式を用いる。
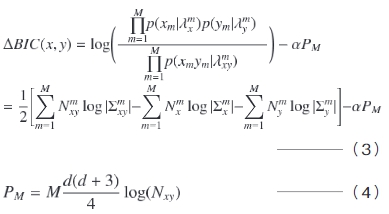
ここで,Mは音素クラスの数,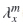 (m=1, …, M)は,特徴ベクトル列xのうち,音素認識による音素情報をもとにm番目の音素クラスに分類された特徴ベクトルの統計量を示す。従来の(1)式および(2)式のフレーム数Nと共分散行列Σで表現される,音素クラスに分類しない「全音素」モデルを用いた手法に対して,本提案手法は,(3)式および(4)式の各音素クラスmのフレーム数Nmと共分散行列Σmで表現される「マルチ音素クラス」モデルにより話者交代点の検出および話者判定を行う。
(m=1, …, M)は,特徴ベクトル列xのうち,音素認識による音素情報をもとにm番目の音素クラスに分類された特徴ベクトルの統計量を示す。従来の(1)式および(2)式のフレーム数Nと共分散行列Σで表現される,音素クラスに分類しない「全音素」モデルを用いた手法に対して,本提案手法は,(3)式および(4)式の各音素クラスmのフレーム数Nmと共分散行列Σmで表現される「マルチ音素クラス」モデルにより話者交代点の検出および話者判定を行う。
3.2 話者交代点検出
音素認識によって,音素境界の時刻(音声フレーム)の集合Thyp={tlast, …, tc}が得られ,それぞれの音素境界前後での話者交代の有無を判定する。ここで,tlastは前回確定した話者交代点,tcは現時刻を示す。話者交代点の候補を音素境界に制限13) することで,交代点検出のための演算量を削減することができ,次の(5)式および(6)式を満たす音素境界thを話者交代点とする。
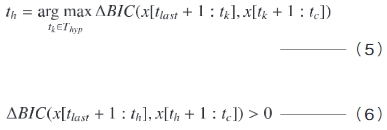
ここで,x[t: ]は時刻tからまでの特徴ベクトル列を示す。このようにして検出される話者交代点の情報は,後段の話者判定部に送られ,話者判定に利用される。
]は時刻tからまでの特徴ベクトル列を示す。このようにして検出される話者交代点の情報は,後段の話者判定部に送られ,話者判定に利用される。
3.3 話者判定
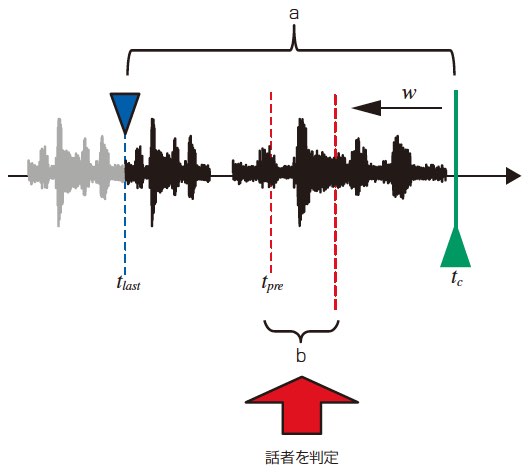
リアルタイムに音声認識を行うためには,時刻tcから一定の遅れ時間wで話者を判定する必要がある。判定手法の概要を2図に示す。可能な限り長い音声区間から精度良く判定を行うために,x[tlast+1:tc](2図の音声区間a)の統計量を用いてx[tpre+1:tc-w](2図の音声区間b)の話者を判定する。ここで,tpreは話者の判定が終了している最終時刻を示す。登録された話者の特徴量の分布モデル(話者モデル)の集合をC(話者未登録の場合は空集合),登録された話者の番号をi,話者モデルλxiに対応する平均特徴ベクトル列をとしたとき,
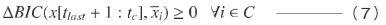
であれば,x[tpre+1:tc-w]は新規話者と判定する。式(7)が満たされなければ,既に登録済みの

を発話者と判定する。話者モデルλxiの更新および新規話者モデルの作成は,話者交代点が検出されるごとに交代点以前の音声を用いて行う。
4. 話者ダイアライゼーション結果を利用した話者適応
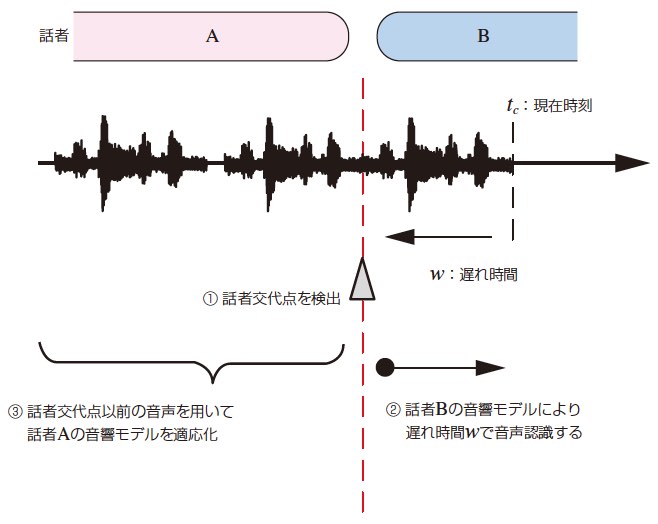
提案手法では,時刻tc に対して遅れ時間w で話者を判定し,その判定結果を利用して同区間の音声認識を行う。話者交代が発生した際には,話者ダイアライゼーションの話者モデルと同様,話者交代以前の音声と認識結果を用いて音響モデルを適応化する。話者交代発生時の音声認識および話者適応の流れを3図に示し,手順を以下に述べる。
- 時刻tcに対して遅れ時間wで,話者交代を検出する(3図では話者Aから話者Bへ交代)。
- 交代以後の話者Bの音響モデルを用いて,時刻tc-w以降の入力音声を認識する。ここで,話者Bが新規話者であれば,性別依存の不特定話者の音響モデルで音声認識する。
- 話者Aの,音声認識開始時から検出した交代点までのすべての音声および音声認識結果を用いて,性別依存の不特定話者の音響モデルを話者Aの音響モデルへ適応化する。この適応化された音響モデルは,次に話者Aが発話したと判定された際に音声認識で利用する。
以上,話者交代が検出されるごとに①~③の処理を繰り返し実行する。
5. 話者ダイアライゼーション実験
5.1 実験条件
対談番組の話者ダイアライゼーション実験により,提案手法の有効性を示す。話者ダイアライゼーションの評価指標には,DER(Diarization Error Rate)を用いた11)。DERは以下の式で定義される。

ここで,FS(False alarm Speech)は発話者なしの区間で発話と誤判定した時間,MS(Missed Speech)は発話者ありの区間で発話なしと誤判定した時間,SE(Speaker Error)は話者を誤った時間,Tは総発話時間を示す。
評価データには2008年5月放送のNHKの報道系情報番組「クローズアップ現代」の対談部分(総発話時間3,177秒,12,356単語,話者10名,話者交代数120)を用いた。評価データ内の話者交代点付近などにおける複数話者の発話のオーバーラップ区間は,合計で11秒(総発話時間の0.3%)存在した。オーバーラップ区間の話者判定の正解は「発話者なし」として,FSとMSを算出した。また,比較手法ごとのΔBICのPおよびPMの重みαを決定するために,評価データの前週の同番組を開発データとして使用した。音素認識には参考文献8) で提案された手法を用いた。音素認識率は57%であり,1表に示した音素クラスの認識率は73%であった。上記FS,MSは音素認識による発話区間検出で決定され,それぞれ総発話時間の0.4%,0.6%であった。
番組キャスター1名の話者モデルはあらかじめ同番組の対談部分(31時間)から作成し,システムの動作開始時の話者モデルとして登録した。その他の話者に関しては,システムの動作中に新規話者モデルとして順次作成し,登録した。話者ダイアライゼーションの基準であるBICで用いるモデルは,音響特徴量を音素クラスに分類しない従来の「全音素」モデル((1)式および(2)式)に対して,母音と鼻音に対応した音響特徴量のみによる「母音+鼻音クラス」モデル((3)式および(4)式の音素クラス数M=1),子音に対応した音響特徴量のみによる「子音クラス」モデル(M=1),母音+鼻音と,子音の2クラスに分類された音響特徴量による「マルチ音素クラス」モデル(M=2)について比較した。
5.2 実験結果
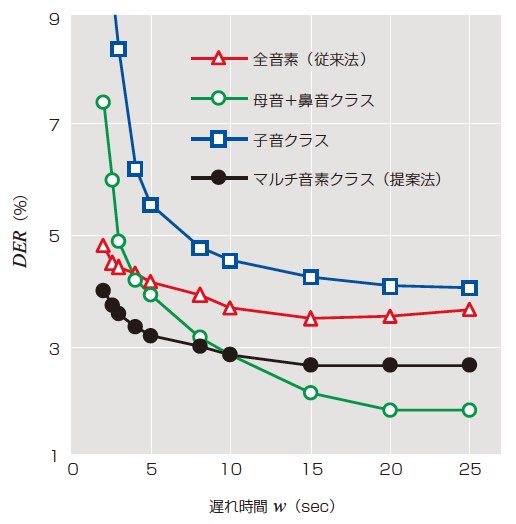
判定の遅れ時間wを変化させたときのDERを4図に示す。図の横軸は遅れ時間wであり,音素認識で判定された無音区間は除かれている。
wが15~25秒では,「母音+鼻音クラス」のDERが最も低かった。これは,遅れ時間が大きく判定のための音響特徴量が十分に得られる場合には,「母音+鼻音クラス」モデルが「子音クラス」モデルよりも多くの個人性を含んでいるため話者ダイアライゼーションに最も有効であることを示している。wが3秒から2秒へ短くなると,「母音+鼻音クラス」はDERが4.9%から7.4%へ,「子音クラス」は8.4%から11.3%へと悪化した。一方,「マルチ音素クラス」では,DERに大きな悪化は見られなかった。これは,「マルチ音素クラス」が判定対象の音声区間内の一部の情報に限定することなく,音声区間全体の情報を活用して話者ダイアライゼーションを行うためと考えられる。
また,「マルチ音素クラス」は,全てのwについて,従来の「全音素」に比べてDERが低く,wが2秒ではDERが4.8%から4.0%へ改善した(誤り削減率20.0%)。特にwが2~8秒では,「マルチ音素クラス」のDERが全手法の中で最も低かった。
6. 話者適応実験
6.1 実験条件
話者ダイアライゼーションにより得られる話者情報を用いて,音響モデルの話者適応実験を行い,提案手法による話者ダイアライゼーションの精度向上が音声認識の精度向上につながることを示す。評価データとして,話者ダイアライゼーション実験と同じ「クローズアップ現代」の対談部分を用いた。
不特定話者の音響モデルは,NHKのニュース番組(男性340時間,女性250時間)から男女別に学習した。番組キャスター1名の音響モデルは,話者モデルと同様に,あらかじめクローズアップ現代の対談部分(31時間)から学習し,話者ダイアライゼーションで番組キャスターの発声区間と判定された部分の音声認識に使用した。この番組キャスターの音響モデルは,既に十分な音声データにより適応化済みと考え,システム動作中の適応は行わないこととした。それ以外の話者の音響モデルについては,性別依存の不特定話者の音響モデルを元に,話者交代ごとに最尤線形回帰(Maximum Likelihood Linear Regression:MLLR)14)*6 を用いて適応化した。音声認識は,これら話者ごとの音響モデルのうち,遅れ時間wで判定される話者情報に対応した音響モデルを用いて,認識結果を確定した。
認識実験は,話者適応を行わない場合と,話者が既知として話者適応を行った場合,そして遅れ時間wが2秒,5秒,10秒の話者ダイアライゼーション結果から話者適応を行った場合について評価した。遅れ時間wを変化させた場合においては,従来法である「全音素」モデルと,提案手法の「マルチ音素クラス」モデルについて比較した。
6.2 実験結果
話者適応による音声認識実験の結果を2表に示す。話者適応なしの場合に比べ,話者ダイアライゼーションを利用した話者適応による音声認識性能の向上が確認された。遅れ時間wが長く,話者ダイアライゼーション精度が良いほど,認識率が向上する傾向が見られた。提案する話者適応手法では,ダイアライゼーション結果に基づいて音響モデルの話者適応を行っているため,話者の推定精度が良いほど,適応化された音響モデルの精度も改善する。よって,ダイアライゼーション精度が向上した音声区間だけでなく,それ以外の音声区間においても,適応化音響モデルによる認識精度の向上が確認された。また,遅れ時間wが短いほど(特に2秒では),話者ダイアライゼーションの精度が悪化するため,話者適応の効果は小さくなった。これは,2~3秒では話者交代点を検出するために十分な情報が得られず,話者交代直後の次の発話者の判定が遅れてしまうことが多いためである。この判定の遅れが,認識時の音響モデルの切り替えタイミングの遅れとなり,認識精度に影響を与えたものと考えられる。
BICの音素クラスについては,全てのwについて「全音素」よりも「マルチ音素クラス」の単語誤り率が小さくなった。遅れ時間wが短いほど,話者交代点付近の話者ダイアライゼーション精度が認識時の音響モデルの切り替えに影響を与えることから,wが2秒において,全話者交代点の前後1発話に関して単語誤り率を算出したところ,「全音素」の24.4%に対して「マルチ音素クラス」は22.5%となった。これは単語誤り削減率7.8%に相当する
| 話者適応 なし |
話者適応あり | ||||||
|---|---|---|---|---|---|---|---|
| 話者が 既知 |
話者ダイアライゼーション=「全音素」 (従来手法) |
話者ダイアライゼーション=「マルチ音素クラス」 (提案法) |
|||||
| w=2 (DER=4.8%) |
w=5 (DER=4.1%) |
w=10 (DER=3.7%) |
w=2 (DER=4.0%) |
w=5 (DER=3.2%) |
w=10 (DER=2.8%) |
||
| 21.7 | 19.4 | 20.4 | 20.0 | 20.0 | 20.2 | 19.9 | 19.9 |
7.あとがき
対談音声認識のための,マルチ音素クラスのベイズ情報量基準に基づく話者ダイアライゼーション手法を提案した。報道系情報番組の対談部分を対象とした実験の結果,遅れ時間2秒の判定において,マルチ音素クラスによる提案手法により,従来手法に比べて20.0%の誤り削減率を得た。さらに,話者ダイアライゼーションにより得られる話者情報に基づく音声認識の話者適応手法を提案した。話者適応実験の結果,遅れ時間2秒において,話者交代点前後の発話に関して単語誤り削減率7.8%が得られた。これにより,提案手法による話者ダイアライゼーションの精度向上が,話者適応による音声認識の精度向上につながることを確認できた。
本稿は,電子情報通信学会論文誌Dに掲載された以下の論文を元に,一部の表現を平易に改めるとともに補足説明を加えたものである。
奥,佐藤,小林,本間,今井:“マルチ音素クラスのベイズ情報量基準に基づくオンライン話者ダイアライゼーション,” 信学論,Vol.J95-D,No.9,pp.1749-1758(2012)