リアルタイム字幕放送のための音声認識
テレビ番組の音声を文字で伝える字幕放送は聴覚障害者や高齢者への有用な情報提供手段となっており,生放送番組へのリアルタイム字幕付与も音声認識技術や高速入力用キーボードの利用によって年々拡充が図られている。本稿では,字幕放送の現状と音声認識技術の概要について述べるとともに,音声認識を利用したリアルタイム字幕制作システムを紹介する。また,認識性能と運用性を向上させるための当所の最近の音声認識の研究について述べ,今後の技術的課題を考察する。
1. まえがき
字幕放送はテレビ番組のナレーションやドラマのせりふなどの音声を文字にして伝える放送で,テレビの音が聞き取りにくい高齢の方や聴覚に障害のある方への重要な情報提供手段となっている。字幕放送は視聴者の好みで字幕を表示するかしないかの選択が可能なクローズド・キャプションである。アナログ放送では字幕を見るために専用の文字放送受信機が必要であったが,デジタル放送では字幕表示機能が受信機に標準で装備されており,リモコンの「字幕」というボタンを押せば字幕が画面に表示される。ワンセグ携帯端末も字幕を表示することが可能で,電車の中など音を出せない場所では健聴者も字幕を利用している。字幕はまさにユニバーサルな情報提供手段となっている。
この字幕には,事前収録番組へ字幕を付けるオフライン字幕と生放送番組へ字幕を付けるリアルタイム字幕とがある。放送前に字幕が完成しているオフライン字幕に対しては技術的な困難性はないが,リアルタイムで字幕を付けることは長い間技術的に困難であった。しかし,近年の音声認識技術の進展や高速入力用キーボードの利用によって,リアルタイム字幕放送の拡充も進んでいる。
当所では,さまざまな生放送番組の字幕(生字幕)を効率よく制作するために,リアルタイム音声認識の研究を行っている。これまでにニュース番組のアナウンサーによる原稿読み上げ部分を直接認識するダイレクト方式や,スポーツ番組の実況アナウンス等を背景雑音のない部屋で別の話者が言い直した音声を認識するリスピーク方式の生字幕制作システムを開発し,実用化している。本稿では,字幕放送の現状と音声認識技術の概要を解説するとともに,リアルタイム字幕放送のための音声認識技術について,これまでにNHKで実用化した上記の方式や現在検討中のシステムを紹介する。また,認識性能と運用性を向上させるために行っている最近の音声認識技術の研究について述べ,今後の技術的課題を考察する。
2. 字幕放送の現状
字幕放送は年々拡充されてきているが,全ての番組に字幕が付与されてはいない。総務省のまとめによれば,2010年度の総放送時間に占める字幕放送時間の割合はNHK総合テレビ(デジタル)で56.2%,民放在京キー5局(デジタル)平均で43.8%である1)。字幕放送を普及させるために,総務省が2007年に策定した字幕放送普及行政の指針2) では,字幕付与が困難な番組,例えば,討論番組など複数の人が同時に会話を行う生番組のような番組を除いて,7時~24時に放送される生放送を含む全ての番組に2017年度までに字幕を付与することを目標としている。NHK総合テレビの2010年度の目標対象番組に対する字幕付与の割合は62.2%であり1),当所では,目標達成へ向けて効率的に字幕制作を行うための研究を進めている。
放送番組には,ドラマやドキュメンタリーなどの放送前に完成している事前収録番組とニュースやスポーツなどの生放送番組があり,それぞれ字幕制作手法が異なる。NHK総合テレビの場合,7時~24時の間では,平均で全体の約4割を占めている事前収録番組の全てに字幕が付いている。この字幕を付けるために,パソコンを利用して人手で文字を入力する他,字幕表示位置やタイミング,文字色などの調整を人手を掛けて入念に行っている。
一方,生字幕を付けるためには,リアルタイムで文字を入力する必要がある。アメリカの放送局では,裁判所の速記入力用に開発されたキーボードを使って専門のオペレーターが1人で字幕の文字を入力することが一般的である。一方,日本語には同音異義語が多く,仮名漢字変換の必要もあり,1人のオペレーターが通常のパソコンのキーボードを使って文字を入力することは困難である。
そこで,NHKでは,現在,キーボードと音声認識を利用した下記の4つのリアルタイム字幕制作方式を番組に応じて使い分けている。
- 通常のキーボードを利用する連携入力方式3) で,複数の入力者が短時間ごとに分担してリレーしながら文字を入力する方式【歌謡番組と情報番組で利用】
- 複数キーを同時に押す特殊な高速入力用キーボード(ステノワード4))を利用する方式で,入力者と校正者の数組のペアが短時間ごとに分担してリレーしながら入力する方式【ニュースなど報道番組で利用】
- 番組音声を直接認識し文字に変換するダイレクト方式5)【大リーグと2000年~2006年のニュースで利用】
- 字幕専用アナウンサーが言い直した音声を認識し,文字に変換するリスピーク方式6)【相撲や野球などのスポーツと情報番組で利用】
キーボード入力方式では,番組の話題や発話スタイル,背景雑音等に依存せずオペレーターが自由に文字を入力できるが,熟練した専門オペレーターが複数人必要である。一方,音声認識を用いた方式では,番組ごとに辞書の事前学習を必要とし,発話スタイルや背景雑音等の影響を受け,十分な認識精度が得られない場合もあるので,適用可能な番組は限定されるが,リスピークや誤り修正の人材を比較的確保しやすいという利点がある。
3. 音声認識技術の概要
コンピューターが人の声を認識して,それを文字に変換したり,話者の意図をくみ取って機器を制御したりする技術が自動音声認識技術である。あらかじめ大量のテキストと音声を認識装置に学習させておき,学習した単語の中から,話した言葉に1番近い単語を選び出す「確率統計的手法」が現在の音声認識手法の主流である。この手法を用いることによって,カーナビやロボット制御,字幕制作など,それぞれ用途が限定されてはいるが,事前に声の登録を必要としない不特定多数話者による数万単語のリアルタイム連続音声認識が可能になっている。以下,一般的な連続音声認識の処理手順について解説する。
3.1 音響モデル
人の耳は音に含まれる周波数成分を分析して利用している。これと同じように,自動音声認識でも時々刻々と変化する音の周波数成分を「音響分析」と呼ばれる信号処理で分析し,発話内容と関連の深い「音響特徴量」(スペクトルの山谷の形を表す係数)を抽出する。人の声は母音や子音ごとに周波数成分が大きく異なるので,これを音響特徴量として音声認識に利用している。ただし,人の耳には同じように聞こえる音,例えば,同じ話者が同じ単語を話した場合であっても,音響特徴量の物理的な値は同じではなく,音の時間的な長さも異なっている。前後の母音・子音の違いや,混入する背景雑音によっても音の周波数成分は大きな影響を受ける。
そこで,どの範囲までの音響特徴量の広がりを同じ母音や子音と見なすのかということを,大量の音声を与えて統計的に「学習」する。字幕制作のための音声認識では,さまざまな話者の声の特徴の広がりを表現するために,数百時間分の放送音声の音響特徴量から「音響モデル」と呼ばれる確率統計モデル(隠れマルコフモデルHMM:Hidden Markov Model)を学習する。認識性能を向上させるためには,本番に近い音声を大量に収集し,より良い学習アルゴリズムで音響モデルを学習させることが重要である。
3.2 言語モデル
発声された複数単語のフレーズや文を認識する連続音声認識では,語彙として学習されている各単語同士のつながりやすさを利用する。例えば,「地球」→「温暖化」や,「して」→「います」など,各単語の次につながる単語には傾向があるので,その統計的な性質を確率値(例えば,0.8や0.3など)で表現しておき,これを「言語モデル(辞書)」(N単語連鎖の出現確率を表すNグラム言語モデル)として利用する。あらかじめ大量のテキストを分析し,字幕制作の対象番組に現れそうな単語や言い回しを言語モデルに「学習」させておく。ここでも,認識性能を向上させるためには,本番の言い回しや内容に近いテキストを大量に収集し,言語モデルを学習させておくことが重要である。また,語彙として学習されていない単語は原理的に認識できないので,本番で新出単語が出てこないように,入念に言語モデルを学習しておくことが大事である。
3.3 単語探索
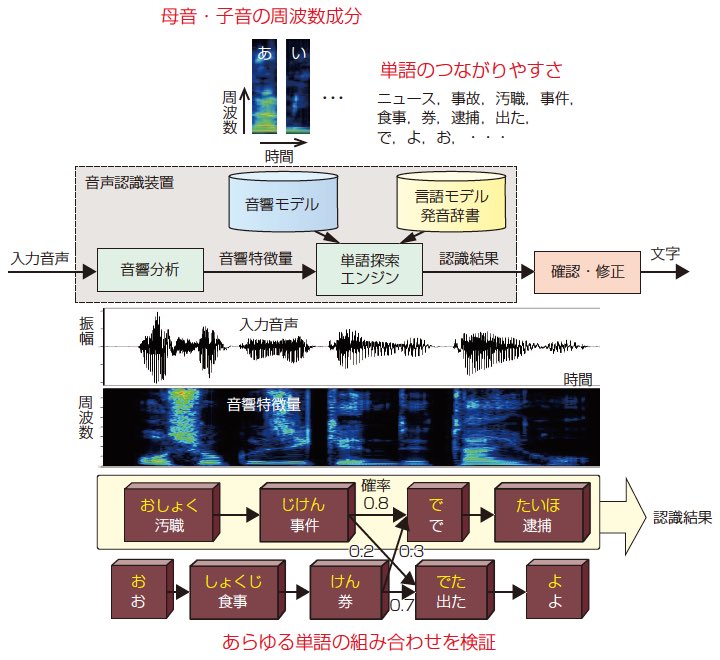
音響モデルは声の特徴を表しているデータの集合であり,言語モデルは単語のつながりやすさを表しているデータの集合である。従って,入力された音声を自動的に認識するためには,まず,1図に示すように,入力音声の音響的な特徴(周波数成分)を分析し,分析した音響的な特徴が辞書に登録されているどの単語(一般には数万単語)の発音に近いのかを音響モデルで計算して候補となる単語を絞り込む。次に,音響的に可能性のあるこれらの単語のうち,どの単語とどの単語がつながりやすいのかを言語モデルを参照して,候補となる単語を絞り込む。このとき,同音異義語は前後関係によって決定する。音声が入力されると,コンピューターはこのような音響的な単語の絞り込みと言語的な単語の絞り込みを繰り返し,膨大な単語の組み合わせを検証する。そして最大の確率が得られる単語の組み合わせを認識結果として出力する。生字幕制作では,音声入力から字幕表示までの遅れ時間をできるだけ短くする必要があり,当所の単語探索アルゴリズムでは,発話の終了を待たずに認識結果を逐次早期確定7) している。
このように,当所で開発した音声認識の処理手順では,ボトムアップ的に母音・子音を認識して仮名に変換し,それから仮名漢字変換を行っているのではない。あらかじめ単語は漢字仮名交じり表記で発音記号列(母音と子音の組み合わせ)と共に辞書に登録されており,音響的な確率と言語的な確率を基に,トップダウン的に最も可能性の高い単語表記の組み合せを認識結果として出力している。
4. 音声認識によるリアルタイム字幕制作システム
NHKがこれまでに実用化した音声認識によるリアルタイム字幕制作システムには,番組音声を直接認識するダイレクト方式と字幕専用のアナウンサーが言い直した音声を認識するリスピーク方式の2種類がある。ここでは,この2種類の方式を紹介するとともに,今後,ニュース番組で実用化予定の,上記の方式を組み合わせたハイブリッド方式を紹介する。
4.1 ダイレクト方式
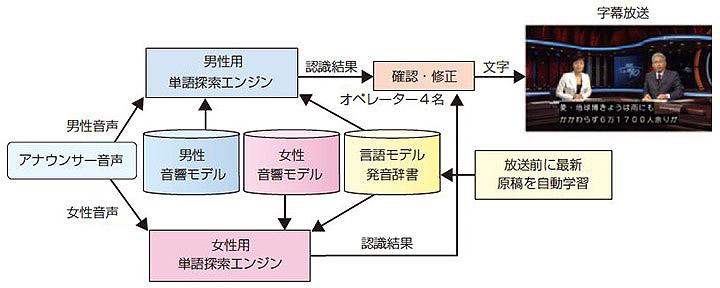
2000年に,世界に先駆けて,ダイレクト方式の音声認識による字幕制作をニュース番組用字幕制作システム5) で実用化した(2図)。当時,実用化レベルの認識率95%に達したのはアナウンサーの原稿読み上げ部分だけであり,部分的な運用ではあったが,日本で初めての生放送番組へ字幕が付与されたことには大きな反響があった。このシステムは,2図に示すように男女別々の音声認識装置で構成され,認識結果の確認と修正を4名のオペレーター(誤り発見者と修正者のペア2組)が担当し,誤りがあればタッチパネルやキーボードで即座に修正して放送した。なお,音声認識装置は,放送直前に最新のニュース原稿(読み原稿用に手書きで加筆修正される前の電子原稿)を自動的に取得し,言語モデルを重み付け学習した8)。
その後,アナウンサーが原稿を読み上げる部分以外の中継や対談部分で特殊な高速入力用キーボード(ステノワード4))による方式が採用され,部分によって制作手段を使い分けた。音声認識は原稿読み上げ部分の限定的な運用だったこともあり,2006年にはNHKのニュース番組は高速入力用キーボードによる字幕制作方式に一本化されている。
現在,ダイレクト方式は日本のスタジオで実況アナウンスを行う大リーグ野球の中継で利用されている。
4.2 リスピーク方式
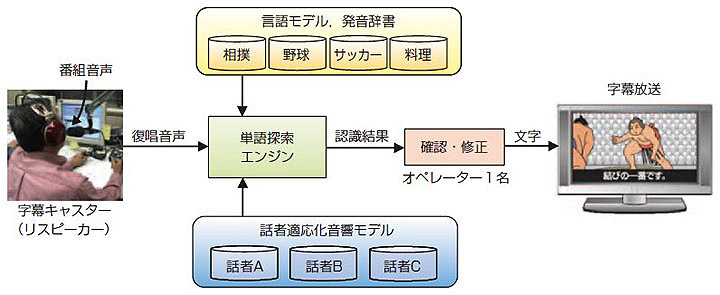
ニュース以外のスポーツや情報番組などの生放送番組に字幕を付けるために,NHKはメーカーと共同でリスピーク方式の生字幕制作システムを開発した(3図)9)。2001年の紅白歌合戦から,オリンピック,W杯サッカー,大相撲,プロ野球などでこの方式を利用して字幕を付けている10)。リスピーク方式では,字幕専用のアナウンサー(字幕キャスター)がヘッドホンで番組音声を聞きながら,番組中の実況アナウンサーや解説者の言葉を復唱するとともに内容を要約する。背景雑音が大きい番組や出演者が複数いるような番組でも,静かなスタジオで字幕キャスターが内容をアレンジして発話するので,十分な音声認識精度が得られ,字幕付与が可能となる。また,スポーツ番組では,字幕の表示遅れ(5秒~10秒)をなるべく短くし,読んで分かりやすい字幕にするために,見て分かることは省略し,内容を簡潔にまとめて言い換えたり6),実況アナウンサーが説明しない拍手や歓声など場内の様子を補足したりしている。また,誤った認識結果が得られた部分は字幕キャスターが再発声して修正することが多く,1人のオペレーターで誤りを修正している。
音声認識で用いる言語モデルは,3図に示すように,番組ジャンルごとに学習テキストを用意し,各番組専用に学習する。また,字幕キャスターごとに適応学習した音響モデルを利用し,認識率の向上を図っている。生放送中に別の字幕キャスターに交代する際にもオンライン処理を中断することなく,音響モデルを即座に切り替えられるようになっている。
4.3 ハイブリッド方式
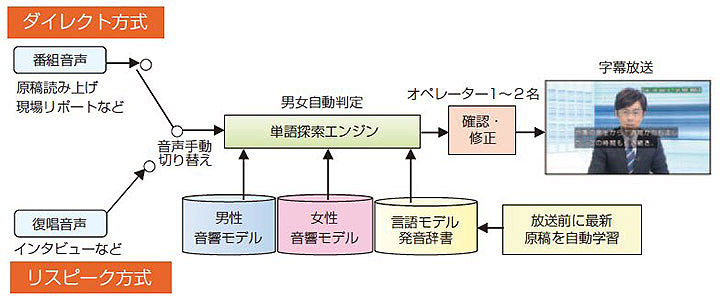
ニュース番組の場合,スタジオアナウンサーの原稿読み上げや記者による現場リポート,更に,アナウンサーと記者の対談部分の音声認識性能は現状の音声認識技術で実用化レベル(平均単語認識率95%以上)にある。一方,それ以外のインタビューや編集済みのビデオや自由発話の多い対談などは,大きな背景音や音楽,不明瞭な発声,速い話し方,砕けた話し言葉などの影響があり,認識性能が低下する。
そこで,認識率の高い部分では音声を直接認識するダイレクト方式を利用し,それ以外のインタビューなどの部分ではリスピーク方式を併用するハイブリッド方式の生字幕制作システム11)の開発を進めてきた(4図)。音声認識装置への入力音声を番組音声とするかリスピーク音声とするかはリスピーカー自身が手動で切り替える。ただし,切り替え時に発話の冒頭が欠落しないように,音声をバッファリングしている。また,認識結果の確認と修正を同時に複数のオペレーターで行えるようにインターフェースを改善し11)12),字幕制作の難しさに応じてオペレーターの数を増減(1~2名)できるようにしている。ハイブリッド方式にすることで,従来は困難であった音声認識だけによるニュース番組全体の字幕付与が可能になる。また,男女の自動判定など,最近の音声認識の要素技術を改善し,認識性能と運用性を向上させている。ハイブリッド方式は効率的で運用コストの低い字幕制作システムとして期待されており,今後,ニュース番組での実用化が予定されている。また,東日本大震災後のニュース番組では,字幕による情報提供を充実させるために,当所で試作したハイブリッド方式のシステムを放送センターに臨時で設置し,ニュース番組の一部で字幕制作に使用した。
5. 音声認識の改善研究
リアルタイム字幕制作に利用する音声認識技術に求められる要件は①正確さ,②リアルタイム性,③効率的な確認・修正,④事前準備の容易さなどである。そのため,ハイブリッド方式の音声認識をニュース番組の字幕制作に活用するために下記に述べる改善を行った。①の正確さに関しては,発話区間検出および男女並列音声認識13),発声の変形を考慮した音響モデルの選択的識別学習14)15),言語モデルの自動更新16) 等の技術を導入して改善した。②のリアルタイム性に関しては,計算処理の低減化を図り,字幕表示までの遅れ時間を短縮した。③の効率的な確認・修正に関しては,インターフェースを改善11)12) し,操作性を向上させるとともにオペレーターの数を削減した。④の事前準備の容易さについては,5.3節で述べる。
この他,出演者の対談や砕けた会話口調などの自由発話音声の認識性能を改善するために,自由発話中の同等表現の言い回しをカバーする方法17) や話者識別を利用した話者適応化18),認識誤りの傾向を学習して認識率の向上を図る識別的リスコアリング19)*1についても研究を進めている。本稿では,言語モデルの自動更新と自由発話の同等表現対策について紹介する。また,発話検出および男女並列音声認識と識別的リスコアリングの詳細については本特集号の報告「字幕制作のためのオンライン発話検出と男女並列音声認識」と「単語誤り最小化に基づく識別的リスコアリングによる音声認識」を参照していただきたい。
5.1 言語モデルの自動更新16)
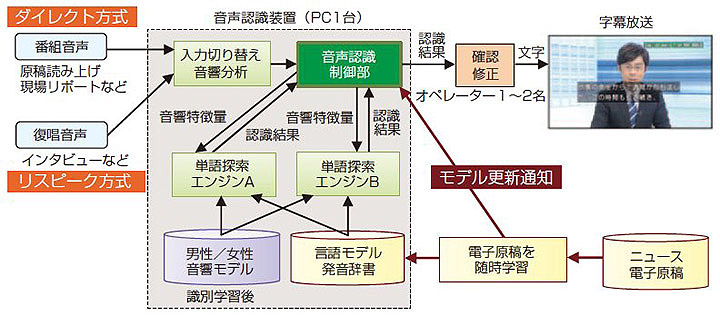
ニュース番組の字幕制作では,新たな固有名詞や話題に即座に対応させて,認識誤りを削減する必要がある。そのために,ニュースアナウンサーの読み上げ原稿の元となる電子原稿を言語モデルの適応学習データに利用して,言語モデルや発音辞書を常に最新の電子原稿で適応学習させている。ニュース番組の放送中であっても,随時,電子原稿を読み込んで学習できるようにするために,ハイブリッド方式字幕制作システムの構成を一部変更した(5図)。従来は,ニュース原稿または言語モデルの更新に合わせて,単語探索エンジンを再起動していたが,新しいシステムでは音声認識制御部が言語モデルの更新に合わせて2つ目の単語探索エンジンを起動し,途切れることなく最新モデルに切り替えられるようにした。これにより,放送中であっても最新の言語モデルを使って途切れのない字幕制作が可能となり,認識誤りを約1/3に削減することができた。また,運用性も大幅に向上した。
5.2 自由発話の同等表現対策17)
対談番組などでは,ゲスト出演者の砕けた言い回しや不明瞭で早口の発声が多く,標準語で明瞭に発声されている学習音声とは言語的および音響的に大きな違いがある。認識率を向上させるためには,このミスマッチを解消する必要がある。そこで,1つの話題についてゲスト出演者が自由に発話している報道系対談番組「クローズアップ現代」のゲストとの対談部分の認識を評価タスクに選び,改善研究を進めた。
言語モデルの学習データの多くは書き言葉調で,話し言葉特有の口語表現が十分に学習されていない。この言語的なミスマッチを解消するために,話し言葉特有のフレーズのうち,同じ意味を持つ同等表現のフレーズを抽出し,言語モデルで得られる単語の出現確率を補正する手法を検討した。例えば,Nグラム言語モデルのうち,話し言葉の「~っていう」を書き言葉の「~という」の確率値と共に平均化し,両者を同一の表現と見なして単語探索することとした。また,音響的なミスマッチを解消するために,話し言葉に特有の認識誤り傾向を音響モデルに反映させる学習を行った。
このようなさまざまな自由発話音声認識の対策を組み合わせた結果,上記の評価タスクに対する単語認識誤り率を24.5%から11.3%へと半減させることができた(誤り削減率54%)。
5.3 今後の課題
リアルタイム字幕放送のための大語彙連続音声認識技術はニュースやスポーツ,情報番組などでは実用レベルに達したが,残念ながら全ての番組で実用できるほどのレベルではない。一般に音声認識性能は「誰が(話者:Who)」「何を(内容:What)」「どこで(音響環境:Where)」「どのように(発話スタイル:How)」発声した音声なのか,すなわち,3W1Hの条件に左右されると考えられる(1表)。現状のダイレクト方式の音声認識でほぼ90%以上の認識率が得られているのは,1表の中央より左側の条件に限られている。現在,「クローズアップ現代」や話題が多様に変化するワイドショーなどの情報番組を対象に改善研究を進めている。
リアルタイム字幕制作では,話者や音響環境,話題へのオンライン適応技術が今後いっそう重要になると考えている。他にも,複数話者の発話のオーバーラップ,言い誤りや言いよどみ,笑い声,外国語音声,背景音楽の問題など,多くの検討課題が残されている。
ニュース番組では記者が入稿した電子原稿を言語モデルの学習に利用できるが,他の生放送番組(特に,ワイドショーなどの情報番組)では番組の大まかな内容が数枚にまとめられた番組構成表の事前情報しか得られないことも多く,現状では学習用関連テキストの収集に多大な労力を要している。そのため,言語モデルの学習用のテキストを十分に得ることのできる番組か,学習データの収集コストを低くできる定期的な番組だけが音声認識で字幕を付与することができる。字幕放送をさまざまな番組に拡充していくためには,事前準備を容易にできるようにし,語彙の選定,新出単語の登録や学習テキストの収集など,音声認識の専門家でなくても効率よく事前準備ができるようにすることも重要である。今後は,構成表程度の少ない番組情報からでも,従来のように事前学習に多大な労力を掛けることなく,多様に変化する話題やリスピーカーの声質に追従して,言語モデルや音響モデルを適応的・自律的に成長させることのできる音声認識システムを構築していきたいと考えている。また,リスピーク方式は現状の音声認識にとって実用的な手法ではあるが,将来的にはダイレクト方式を拡充して字幕制作コストを更に低減させる必要がある。
放送番組の字幕制作においては,音声認識結果に誤りの含まれる可能性が少しでもある限り,認識結果を人手で確認・修正することは欠かせない。音声認識を利用した字幕制作システムでは,修正やリスピークの人間系も含めてシステム全体で誤りを短時間でカバーできるシステムにする必要がある。
| 条件:3W1H | 低い ← 難易度 → 高い |
|---|---|
| 誰が (話者:Who) | アナウンサー 記者 ゲスト出演者 芸能人 一般 |
| 何を (内容:What) | 原稿 話題限定 深い話題 多様性大 話題未定 |
| どこで (音響環境:Where) | スタジオ 低雑音 背景音楽 高雑音 騒音下 |
| どのように (発話スタイル:How) | 読み上げ 明瞭 自発的 不明瞭 談笑 感情的 |
6. あとがき
本稿では,字幕放送の現状と音声認識技術の概要について解説するとともに,リアルタイム字幕放送のための音声認識について,これまでに実用化した各種の方式と現在検討中のシステムを紹介し,最近の研究成果と残された今後の技術的課題を述べた。音声認識による初の生字幕放送を開始して以来,字幕が付与されたことで家族と一緒に楽しめる番組が増えたと聴覚障害者や高齢者から好評を得ているが,現状の音声認識技術は残念ながら全ての番組に字幕を付けることのできるレベルではない。今後は,前述した音響的・言語的なさまざまな課題を解決していく。更に,人間が音声の認識に利用していると考えられる文脈や意味の知識,抑揚などの非言語的な情報や聴覚心理特性などの知見など,これまで自動音声認識では十分に利用されていなかった情報も活用し,より人間に近い音声認識技術を目指していきたい。また,総務省の字幕放送普及目標を確実に達成するために,ローカル放送局でも運用可能ないっそう効率的で運用コストの低い字幕制作システムを開発していく。更に,音声認識技術をメタデータ制作で活用20) することなど,放送分野でのさまざまな展開を検討していきたい。