ビッグデータ利活用技術(4回/全4回)
音声認識技術
ヒューマンインターフェース研究部 小林 彰夫
この連載では、情報通信技術(ICT)分野で注目が集まっているビッグデータについて、放送サービスでの利用に向けたデータ分析技術や処理システムについて紹介します。
音声認識は、音から文字(テキスト)への変換技術です。NHKでは、聴覚に障害のある方や高齢で音声が聞き取りにくい方などへ、テレビ番組の音声を文字で伝えるために音声認識技術を使った字幕放送の制作を進めています*。
音声認識技術を活用すれば、音声から「誰が」「いつ」「何を」話したかという情報が得られるため、放送内容を文字で検索するといった応用など、コンテンツを活用した放送サービス充実への期待が高まっています。
近年、ビッグデータといわれている大量の音声やテキストの利活用が可能になっています。音声認識を用いて利便性の高いサービスを実現する上で、これらの膨大なデータから認識性能の向上につながる情報を引き出すことが課題です。一般に音声認識では、音声から人の声の特徴や、ことばのつながりやすさ(言い回し)を学習することで、音から文字への変換をおこないます(図1)。しかし、言い回しの学習には、音声に対応したテキストを人手による書き起こし作業で作成しなければなりません。放送番組には特有の言い回しがあるため、音声に対応したテキストを音声認識により生成し学習に利用することが可能になれば、認識性能の向上が期待できます。
そこで、技研では、音声認識技術を用いてテキストを生成して、放送番組で使われる言い回しを自動的に学習する研究に取り組んでいます(図1 点線部)。
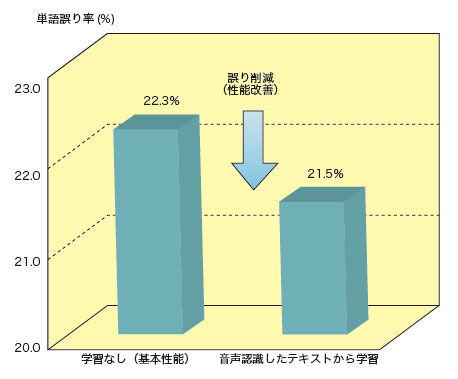
図2は、音声認識で生成した大量のテキストから言い回しを学習したときの認識性能(単語誤り率)の改善結果を示したものです。音声認識したテキストには認識誤りが含まれていますが、大量のテキストから放送番組でよく使われる言い回しを的確に学習することで、認識性能を改善できることが分かりました。
技研では、今後も音声認識技術をさらに発展させ、ビッグデータ時代に向けた放送サービスの充実に向けて研究を進めていきます。
*現在、ニュースやスポーツ中継、あさイチなどの情報番組で音声認識技術を利用しています。