Archive Search System Using Image Analysis Technology
Takahiro Mochizuki
As a way to use video accumulated by broadcasters more effectively independently of manually added text data, we have been researching technology in which image analysis is used to generate metadata for video as well as search technology. We have also verified the utility of the image analysis technology using raw video from the Great East Japan Earthquake and the broadcast archives. This article describes a demonstration of linking this technology to the broadcast archive search system actually used by program producers, gives an overview of the technologies, systems and functionality, and discusses the results of analyzing evaluations and operation logs from real users.
1. Introduction
Broadcasting stations accumulate large volumes of past broadcast video and raw materials in their archives. Such a collection is a treasure house of materials for reuse and reference by program producers, so an effective mechanism to search for a desired video is essential.
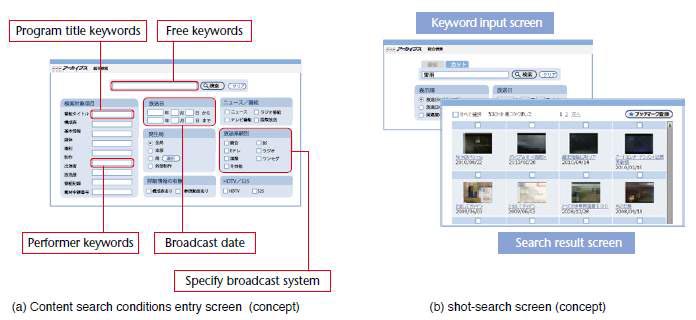
NHK operates an archive information system that enables program producers and their staff to search these archives. Users can search for content (programs) by entering a program title, key words, a broadcast date and other parameters [Fig. 1 (a)]. However, when a user needs a particular short segment, or shot*1, they must visually search for the desired segment in the content found by the search. Therefore, a shot-based keyword search function is also provided in addition to the search by entire content items, whereby text data in closed captions*2 or manually added comments are used [Fig. 1 (b)].
As shown in Fig. 2 (a), only a very small amount of content in the current archive information system has a structure table, which contains video and timing information for each shot, and even less of that content has text information for each shot. Thus, most shots cannot be found using a keyword search. Also, as shown in Fig. 2 (b), keywords based on caption data do not always accurately reflect the video content. The manual application of keywords to shots is not only expensive, but may also not result in finding the desired shots because the keywords applied vary depending on who is doing the work, as shown in Fig. 2 (c). Thus, there are various issues with a search for shots based only on keywords.
We have been researching a search technology based on image analysis as an approach different from the conventional keyword search. For approximately four months starting from January 2015, we operated a trial of a new search system using the analysis of images in the archive information system in order to verify its utility and identify any practical issues (called the “verification-test” below).
There are real examples of image analysis technology from Google and other organizations, but almost no examples of search technologies using image analysis of the large-scale resources at a broadcast station or built into systems used in actual businesses. Even an examination of reports from large-scale international conferences for broadcasters and other video-archive-related enterprises and organizations, such as the FIAT/IFTA World Conference1), reveals the need for image analysis technology, but it has rarely been introduced, so our verification-test is also unprecedented on a global scale.
Two technologies, “automatic object recognition” and “visually-similar-image search,” were introduced in our verification-test. The automatic object recognition technology applies keywords automatically, reducing the cost relative to manual operation and controlling the accuracy and variation in keyword expressions, as discussed earlier. The visually-similar-image search technology enables searches based on similarities among the images themselves without relying on keywords, making it possible to also search images with no associated text data.
Section 2 of this paper first gives an overview of the new automatic object recognition and visually-similar-image search technologies, and discusses mechanisms for accelerating the visually-similar-image search. Section 3 describes the operation of the search trial, and Section 4 describes the usage state and evaluation through interviews with users, and discusses these results.

2. Principal Technologies
The principal technologies introduced in our verificationtest were an automatic object recognition technology (which applies keywords automatically on the basis of object recrecognition), and a visually-similar-image search technology that considers object regions. In addition to these, measures were taken to accelerate the visually-similar-image search. This section gives an overview of each of these.
2.1 Automatic object recognition technology
The automatic object recognition technology automatically determines what is depicted in the video by image analysis. It was introduced in our verification-test with the intention of resolving the issues discussed in Section 1, namely, the high cost of applying keywords, the inaccuracy of keywords taken from captions, and the variation in expressions used for keywords.
One approach to automatic object recognition is to prepare a set of example and counter-example*3 images of each object, and then use a recognition model (such as a support vector machine) that learns to identify objects from the differences in image characteristics in the images (Fig. 3). For image features, sets of local image features, such as scaleinvariant feature transforms (SIFTs)2), expressed as a “bag of features” (BoF)3), are widely recognized as an effective approach.
One local feature method that has attracted attention recently is called geometric phrase pooling (GPP)4). It can compute more robust and expressive image features than earlier methods by considering brightness and edge*4 gradients in the target area and surrounding areas. However, with GPP, issues remain in that broad color and texture*5 characteristics are not represented.
For our verification-test, we used an approach of combining local features based on GPP and broad features such as color and texture5)6). Figure 4 shows how image features are computed by our method. In the figure, locality-constrained linear coding (LLC) quantization is a feature vector quantization method that uses local constraints*6 in the feature vector space, and the color moment feature uses the average, variance and covariance of each color component. The Haar wavelet feature is a texture feature based on the brightness in neighboring rectangular regions, and the local binary pattern (LBP) feature is a texture feature based on the relative magnitudes of each pixel to its neighboring pixels. Our method computes an overall feature vector for the image using local feature values computed by GPP from feature points and the surrounding region, as well as broad features computed from wider areas. These are then integrated by spatial pyramid matching (SPM)7)*7 (Fig. 5).
Figure 6 shows examples of object recognition using these image features applied to the data set from TRECVID8), which is a large-scale international workshop on video analysis. A support vector machine, as described above, was used as the recognition model. The top 20 images (in order from highest probability, as in Fig. 3) for “flag” in Fig. 6 (a) and “boat” in Fig. 6 (b) are shown, and those marked with a red circle were judged to be correctly recognized. In Fig. 6 (a) and 6 (b), there are 19 and 17 correct images, respectively, demonstrating high recognition accuracy. Details regarding this technology can be found in the reference documents9).




2.2 Visually-similar-image search technology
As discussed in Section 1, very little content has associated text information at the level of individual shots, so most cuts cannot be found using a keyword search. This issue can be mitigated by using the automatic object recognition technology discussed in Section 2.1, but there is limited diversity in the object keywords that can be applied. Thus, a visually-similar-image search technology, which can find cut images that are similar in color, texture or overall layout without referring to keywords, is also useful.
Program producers, who are the users of archive searches, tend to focus their searches on the objects portrayed as well as the layout. However, earlier techniques10)11) of dividing images into a grid of blocks and comparing image features (Fig. 7) are not capable of absorbing small differences in layout, so search results do not always meet with the user’s intentions. In the example in Fig. 7, the user was searching for a layout and an object (apple), but the earlier method judged the image of a lemon to be the most similar.
In our verification-test, we place some blocks over the object region rather than on the region grid, as shown in Fig. 8, and increase the weight given to these blocks when computing the image similarity12)13). Object regions are estimated using a saliency map14), which indicates how much regions in the image stand out. Our method can absorb small differences in layout and preserve the overall similarity of images while emphasizing the similarity of the objects in the images.


2.3 High-speed search for visually-similar-images
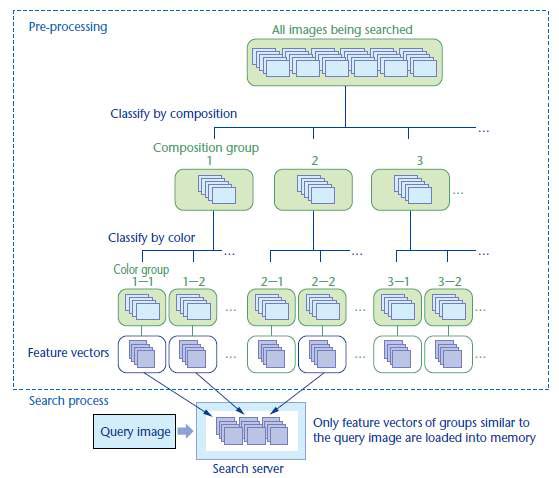
We demonstrate searches on large-scale image data sets containing millions to 10 millions of images. For each visually-similar-image search, the similarity of feature vectors between images must be computed, but with 10 million images, the search process could take up to 30 minutes, so ways to increase this speed were needed. One approach is to load the feature vectors for all images into memory when the search engine starts up, but this would make the startup time long and require a large amount of memory.
We adopted a method15) in which the images being searched are first classified hierarchically by their overall composition and color characteristics. Then, as shown in Fig. 9, only the feature vectors for sets of images in groups that have similarity to the query image*8 above a certain threshold are loaded into memory when performing a search.
This enabled us to reduce the search space, increase the speed and also reduce the memory required. With this technique, approximately 10 million images could be searched in five to ten seconds. An overview of the classification process in Fig. 9 is given below.
First, composition data for all images to be searched is computed using the classification of block regions based on their color features, as in Fig. 10 (a). Then, the images are classified into composition groups based on the similarity of composition data to approximately 80 composition templates. These composition templates were prepared manually, considering composition variations used in broadcast video. Examples of composition templates are shown in Fig. 10 (b).
Then, within each of the composition groups generated, images are classified into color groups based on the similarity of overall color features. The color feature used here is the concatenation of color feature vectors of all blocks in the image. The k-means method*9 was used for this classification, with the number of groups being set in the range of 20 to 200 depending on the number of images in the composition group.

3. Verification-test of the Search System Using Image Analysis
In this section, we describe the system and functionality used in our verification-test over approximately four months from January to April 2015.
3.1 System overview
An overview of the system used in our verification-test is shown in Fig. 11. The new search system applying the technologies introduced in Section 2 (hereinafter called the “image search system”) runs on a separate server from the archive information system, and a separate screen is launched using a link placed on the archive information system screen. Operation in this manner avoids the possibility of affecting the archive information system, even if a fault should occur in the image search system. There is also a mechanism for showing bookmarks registered*10 in the image search system on the archive information system, and video can be played back on the image search system. This enables users to use the image search system in their real work.
For this operation, the image search was applied only to content in the archive information system that had an associated structure table giving timing information for each shot, that had images for each shot, and that can be displayed to all users.
The system is expected to be used in real work, so it is important that the data be “fresh”. Thus, the latest content was added each month, as shown in Table 1, and by the end of the verification-test, the system was able to search approximately 100,000 content items and 10 million shot images.
Processes that enable the search, including computing the image features, generating metadata (keywords, etc., associated with images), and creating indices*11, were performed automatically by a metadata generation system based on the Metadata Production Framework (MPF)16)*12.

| Date | Items added (approx.) |
Total content items (approx.) |
|---|---|---|
| Jan. 27, 2015 (Start of operation) |
57,000 | 57,000 |
| Feb. 27, 2015 | 12,000 | 69,000 |
| Mar. 6, 2015 | 12,000 | 81,000 |
| Mar. 23, 2015 | 10,000 | 91,000 |
| Apr. 8, 2015 | 10,000 | 101,000 |
3.2 Functional overview
In addition to a conventional search by program title or keyword, the top screen of the image search system [Fig. 12 (a)] provides the results of a search by a similar shot image by the upload of a query image using the technology discussed in Section 2.2. The availability of an additional screen allows a search for shots by selecting terms from among 50 object keywords that have been automatically applied using the technology discussed in Section 2.1. The archive information system structure display screen [Fig. 12 (b)] also allows a similar shot image search using the technology described in Section 2.2, where shot images in the structure table are utilized as query images. Selecting search results displays a screen with details of the content containing the shot [Fig. 12 (c)]. This screen enables a search of the content for shot images that are similar to the specified shot using the technology described in Section 2.2.

4. Usage Status, User Evaluation and Discussion
In this section, we discuss the usage status of the image search system on the basis of the analysis of operation logs and evaluations by actual users.
4.1 Usage status
During the verification-test period (late January to early May 2015), the image search system was accessed effectively (resulting in search operations) 1,538 times by 909 people, generating a total of 2,103 search operations. 278 people were “repeaters” accessing the system and conducting searches multiple times. Users were from all NHK stations, totaling over 40 stations, not just the NHK Broadcast Center in Shibuya, Tokyo, so the system was used more widely than expected. By function, searches by uploading an image and by selecting a shot from the structure table on the archive information system had the highest usage rates. This shows that in addition to the conventional keyword search, there is demand for visually-similar-image search technology that does not use keywords.
4.2 User Evaluation and Discussion
The use of the image search system by real users was monitored as follows to evaluate the effectiveness of the system.
- Evaluation period: April 13 to 23, 2015
- Monitored users: Five directors of general programming and news, five program production staff members specializing in searches
- Method: Each person was interviewed for about 30 minutes while they were conducting real search operations
The main comments received in the interviews are shown in Table 2. Overall, users indicated that there was a strong need for this technology. We now discuss the effects of the new technology in light of the interview results.
The main issue raised regarding the current archive information system was the difficulty of conducting the keyword search for shots (support for “overall image”, unreliability of keywords, etc.). In our verification-test, we introduced a visually-similar-image search for shots, and we received comments praising its suitability for image shot searches and its effectiveness for searching content with no attached text information, so it may be an effective technology for resolving the above issues. However, there were requests to place even more emphasis on object similarity, so one future issue will be to make the technique of positioning blocks over object areas even more effective.
We also introduced technology to apply keywords to shot images automatically using object recognition, and we received comments that it was useful for finding many shot images of the same type. Thus, this technology also appears to mitigate some issues, but it will be necessary to add more variation to the object keywords used.
There was also a comment that the current search speed of the visually-similar-image search was adequate, suggesting that introducing this technology was effective. However, users could be frustrated with the current search speed when the system can’t find their desired images. Thus, it will be necessary to improve the search accuracy.
| Search with the current archive information system |
|---|
| I search for content by program title and broadcast date, and then look for shots visually on the structure display screen for each item. |
| When I have to search given an overall idea, video or photo from the director, it is difficult to search using just keywords. |
| I often cannot find what I am looking for using just the current keyword search, so I sometimes don’t use the system and just play back tapes directly. |
| Use cases, merits |
|---|
| It’s good for finding insert image shots that are difficult to express in words, such as scenery. |
| It’s convenient when I need to find many videos of the same type to produce a feature video (such as a cherry blossom feature). |
| I can now search through un-edited materials that have no associated text information, based on images from edited video. |
| I can use a wider variety of shots, because I can search content that has no associated text information. |
| A keyword search might be enough when I know exactly what I am looking for. |
| Usability |
|---|
| It’s convenient to be able to specify shots in the structure display of the archive information system. |
| It’s convenient to search across content for similar items by selecting a shot on the content detail screen. |
| The current speed is acceptable if we can find content that is good (a similar-image search takes 5 to 10 s). |
| Accuracy |
|---|
| Current accuracy was rated at about 3 out of 5, but accuracy varied somewhat depending on the image or keyword. |
| Users are used to Web searches, but high accuracy of 50% or 60% cannot be expected. |
| I don’t expect high accuracy, but I expect the top 2 or 3 items to be hits. |
| When looking for something rare, sometimes it’s okay to find one item out of 100. |
| I usually look at about 3 pages of results (30 items). |
| Demand |
|---|
| Beyond just the appearance of the overall image, I would like to emphasize the similarity of the objects in it. |
| I would like more variation in the object keywords. |
| I would like a function to look for old photos of a person from a face photo. |
5. Conclusions
We described the verification-test of a search system that used image analysis technology and was linked to the NHK archives information system used by program producers. The verification-test was conducted over approximately four months and introduced an object recognition technology that automatically associates keywords with images, a visually-similar-image search technology that performs searches without using keywords, and technologies to accelerate visually-similar-image searches. The system was evaluated by monitoring real users, who indicated that there is a strong need for these technologies. We also obtained information useful for implementing this technology by analyzing operation logs and from the monitoring evaluation.
This verification-test of our search system is revolutionary in that it can handle the large volume of resources held by broadcasters, and that it has been implemented to operate with systems already in operation at broadcast stations. Recently, image analysis technology has been advancing rapidly with the introduction of artificial intelligence (AI) models, and we expect more of this sort of concrete initiative of implementing the latest image analysis technologies in the future.