Research Area
5.1 Automatic closed-captioning technology
Closed-captioning service not only serves the needs of people with hearing disabilities and the elderly by conveying speech in TV programs in text but also offers a useful function to general viewers watching programs in a noisy environment or an environment where audio cannot be played such as public places. Also, there is a demand from viewers for more programs with closed captions, including live broadcast programs and programs produced by regional broadcasting stations. Speech recognition technology is used for real-time closed captioning, but many regional broadcasting stations are faced with issues such as a shortage of staff to correct speech recognition errors and a considerable amount of time required to prepare necessary equipment and system. To address these issues and expand closed-captioning service, we began a trial service that distributes speech recognition results on the internet without correcting recognition errors with the aim of evaluating the extent to which uncorrected speech recognition results can help viewers understand programs.
■Speech recognition technology for internet delivery
A service to deliver uncorrected recognition results on the internet requires a higher recognition accuracy. We therefore employed a speech recognition technology that we developed for the transcription of video footage, which requires a higher level of recognition than for program speech(1). This technology can generate highly precise recognition results sequentially for speech inputs streamed over network without waiting for the end of a sentence. We verified the recognition accuracy of this speech recognition technology when used for news and information programs produced by regional broadcasting stations and demonstrated that a recognition accuracy of 90% to 97% can be achieved for news items and live coverage and information items.
Meanwhile, the recognition accuracy declined significantly for interviews with local residents, which contain inarticulate speech, an accent peculiar to the region or different phrases from those used in standard Japanese. The recognition results of these parts make it difficult to understand the program due to incorrectly recognized words. Also, many interviews in news and information programs are open captioned and do not need additional closed captions. We therefore elaborated a way of presenting closed captions by stopping speech recognition and displaying "..." in closed captions for parts where the recognition accuracy is expected to decline.
The Chinese characters of personal names used in programs produced by regional broadcasting stations cannot be correctly identified in some cases because they are not always the same as those of names used in programs produced in Tokyo, which are used as training data for speech recognition. Therefore, we decided to display personal names in katakana, which is the Japanese phonetic characters.
NHK broadcasts regional programs of each regional broadcasting station in a broadcast time frame starting 6:10 PM on weekdays. Providing this trial service across the nation would require as many sets of speech recognition equipment as there are regional broadcasting stations, incurring a large-scale capital investment and operation costs for the installation and maintenance. We therefore built a system efficiently by aggregating speech recognition and delivery equipment on the cloud (Figure 5-1). We began this trial service in three NHK broadcast stations of Shizuoka, Kumamoto and Fukushima in February 2019.
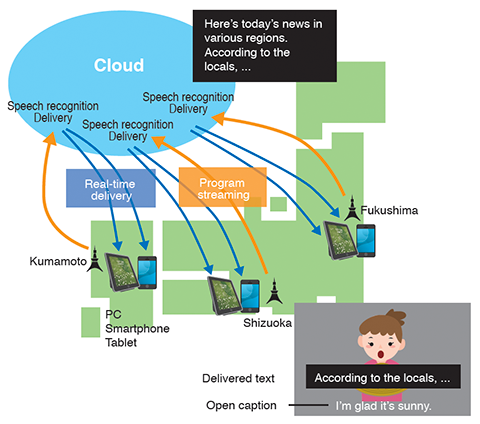
Figure 5-1. System overview
| [References] | |
| (1) | A. Hagiwara, H. Ito, T.Kobayakawa, T. Mishima and S. Sato: "Development of Transcription System Using Speech Recognition for Video Footage," IPSJ SIG Technical Report, Vol. 2018-SLP-124, No. 5, pp.1-6, (2018) (in Japanese) |